
|
Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling
Tal Daniel, Carl Qi, Dan Haramati, Amir Zadeh, Chuan Li, Aviv Tamar, Deepak Pathak, David Held
@inproceedings{
daniel2026latent,
title={Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling},
author={Tal Daniel and Carl Qi and Dan Haramati and Amir Zadeh and Chuan Li and Aviv Tamar and Deepak Pathak and David Held},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=lTaPtGiUUc}
}
We introduce Latent Particle World Model (LPWM), a self-supervised object-centric world model scaled to real-world multi-object datasets and applicable in decision-making. LPWM autonomously discovers keypoints, bounding boxes, and object masks directly from video data, enabling it to learn rich scene decompositions without supervision. Our architecture is trained end-to-end purely from videos and supports flexible conditioning on actions, language, and image goals. LPWM models stochastic particle dynamics via a novel latent action module and achieves state-of-the-art results on diverse real-world and synthetic datasets. Beyond stochastic video modeling, LPWM is readily applicable to decision-making, including goal-conditioned imitation learning, as we demonstrate in the paper.
The Fourteenth International Conference on Learning Representations (ICLR 2026) - Oral Presentation (Selection rate 1.18%)
|

|
Real-World Offline Reinforcement Learning from Vision Language Model Feedback
Sreyas Venkataraman*, Yufei Wang*, Ziyu Wang, Navin Sriram Ravie, Zackory Erickson†, David Held†
@inproceedings{venkataraman2025realworld,
title = {Real-World Offline Reinforcement Learning from Vision Language Model Feedback},
author = {Venkataraman, Sreyas and Wang, Yufei and Wang, Ziyu and Ravie, Navin Sriram and Erickson, Zackory and Held, David},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year = {2025}
}
Offline reinforcement learning can enable policy learning from pre-collected, sub-optimal datasets without online interactions. This makes it ideal for real-world robots and safety-critical scenarios, where collecting online data or expert demonstrations is slow, costly, and risky. However, most existing offline RL works assume the dataset is already labeled with the task rewards, a process that often requires significant human effort, especially when ground-truth states are hard to ascertain (e.g., in the real-world). In this paper, we build on prior work, specifically RL-VLM-F, and propose a novel system that automatically generates reward labels for offline datasets using preference feedback from a vision-language model and a text description of the task. Our method then learns a policy using offline RL with the reward-labeled dataset. We demonstrate the system’s applicability to a complex real-world robot-assisted dressing task, where we first learn a reward function using a vision-language model on a sub-optimal offline dataset, and then we use the learned reward to employ Implicit Q learning to develop an effective dressing policy. Our method also performs well in simulation tasks involving the manipulation of rigid and deformable objects, and significantly outperform baselines such as behavior cloning and inverse RL. In summary, we propose a new system that enables automatic reward labeling and policy learning from unlabeled, sub-optimal offline datasets.
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
|

|
Geometric Red-Teaming for Robotic Manipulation
Divyam Goel, Yufei Wang, Tiancheng Wu, Helen Qiao, Pavel Piliptchak, David Held†, Zackory Erickson†
@misc{goel2025geometricredteamingroboticmanipulation,
title={Geometric Red-Teaming for Robotic Manipulation},
author={Divyam Goel and Yufei Wang and Tiancheng Wu and Guixiu Qiao and Pavel Piliptchak and David Held and Zackory Erickson},
year={2025},
eprint={2509.12379},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2509.12379},
}
Standard evaluation protocols in robotic manipulation typically assess policy performance over curated, in-distribution test sets, offering limited insight into how systems fail under plausible variation. We introduce Geometric Red-Teaming (GRT), a red-teaming framework that probes robustness through object-centric geometric perturbations, automatically generating CrashShapes -- structurally valid, user-constrained mesh deformations that trigger catastrophic failures in pre-trained manipulation policies. The method integrates a Jacobian field-based deformation model with a gradient-free, simulator-in-the-loop optimization strategy. Across insertion, articulation, and grasping tasks, GRT consistently discovers deformations that collapse policy performance, revealing brittle failure modes missed by static benchmarks. By combining task-level policy rollouts with constraint-aware shape exploration, we aim to build a general purpose framework for structured, object-centric robustness evaluation in robotic manipulation. We additionally show that fine-tuning on individual CrashShapes, a process we refer to as blue-teaming, improves task success by up to 60 percentage points on those shapes, while preserving performance on the original object, demonstrating the utility of red-teamed geometries for targeted policy refinement. Finally, we validate both red-teaming and blue-teaming results with a real robotic arm, observing that simulated CrashShapes reduce task success from 90% to as low as 22.5%, and that blue-teaming recovers performance to up to 90% on the corresponding real-world geometry -- closely matching simulation outcomes.
Conference on Robot Learning (CoRL), 2025 - Oral Presentation (Selection rate 5.7%)
|

|
Learn from What We HAVE: History-Aware VErifier that Reasons about Past Interactions Online
Yishu Li, Xinyi Mao, Ying Yuan, Kyutae Sim, Ben Eisner, David Held
@inproceedings{li2025have,
title={Learn from What We HAVE: History-Aware VErifier that Reasons about Past Interactions Online},
author={Li, Yishu and Mao, Xinyi and Yuan, Ying and Sim, Kyutae and Eisner, Ben and Held, David},
booktitle={Conference on Robot Learning (CoRL)},
year={2025}
}
We introduce a novel History-Aware Verifier (HAVE) to solve ambiguous manipulation tasks. Our method works by decoupling action generation from verification: it first proposes multiple candidate actions and then uses the verifier to select the most promising one by reasoning about past interactions. We theoretically and practically proved that the verifier improves the expected performance.
Conference on Robot Learning (CoRL), 2025
|
|
Planning from Point Clouds over Continuous Actions for Multi-object Rearrangement
Kallol Saha*, Amber Li*, Angela Rodriguez-Izquierdo*, Lifan Yu, Ben Eisner, Maxim Likhachev, David Held
@inproceedings{saha2025planning,
title={Planning from Point Clouds over Continuous Actions for Multi-object Rearrangement},
author={Saha, Kallol and Li, Amber and Rodriguez-Izquierdo, Angela and Yu, Lifan and Eisner, Ben and Likhachev, Maxim and Held, David},
booktitle={Conference on Robot Learning (CoRL)},
year={2025}
}
Long-horizon planning for robot manipulation is a challenging problem that requires reasoning about the effects of a sequence of actions on a physical 3D scene. While traditional task planning methods are shown to be effective for long-horizon manipulation, they require discretizing the continuous state and action space into symbolic descriptions of objects, object relationships, and actions. Instead, we propose a hybrid learning-and-planning approach that leverages learned models as domain-specific priors to guide search in high-dimensional continuous action spaces. We introduce SPOT: Search over Point cloud Object Transformations, which plans by searching for a sequence of transformations from an initial scene point cloud to a goal-satisfying point cloud. SPOT samples candidate actions from learned suggesters that operate on partially observed point clouds, eliminating the need to discretize actions or object relationships. We evaluate SPOT on multi-object rearrangement tasks, reporting task planning success and task execution success in both simulation and real-world environments. Our experiments show that SPOT generates successful plans and outperforms a policy-learning approach. We also perform ablations that highlight the importance of search-based planning.
Conference on Robot Learning (CoRL), 2025 - Oral Presentation (Selection rate 5.7%)
|

|
Force-Modulated Visual Policy for Robot-Assisted Dressing with Arm Motions
Alexis Yihong Hao, Yufei Wang, Navin Sriram Ravie, Bharath Hegde, David Held†, Zackory Erickson†
@inproceedings{Hao2025Force,
title={Force-Modulated Visual Policy for Robot-Assisted Dressing with Arm Motions},
author={Hao, Yihong and Wang, Yufei and Ravie, Navin Sriram and Hegde, Bharath and Held, David and Erickson, Zackory},
booktitle={Conference on Robot Learning (CoRL)},
year={2025}
}
Robot-assisted dressing has the potential to significantly improve the lives of individuals with mobility impairments. To ensure an effective and comfortable dressing experience, the robot must be able to handle challenging deformable garments, apply appropriate forces, and adapt to limb movements throughout the dressing process. Prior work often makes simplifying assumptions—such as static human limbs during dressing—which limits real-world applicability. In this work, we develop a robot-assisted dressing system capable of handling partial observations with visual occlusions, as well as robustly adapting to arm motions during the dressing process. Given a policy trained in simulation with partial observations, we propose a method to fine-tune it in the real world using a small amount of data and multi-modal feedback from vision and force sensing, to further improve the policy's adaptability to arm motions and enhance safety. We evaluate our method in simulation with simplified articulated human meshes and in a real world human study with 12 participants across 264 dressing trials. Our policy successfully dresses two long-sleeve everyday garments onto the participants while being adaptive to various kinds of arm motions, and greatly outperforms prior baselines in terms of task completion and user feedback.
Conference on Robot Learning (CoRL), 2025
|

|
ArticuBot: Learning Universal Articulated Object Manipulation Policy via Large Scale Simulation
Yufei Wang*, Ziyu Wang*, Mino Nakura†, Pratik Bhowal†, Chia-Liang Kuo†, Yi-Ting Chen, Zackory Erickson‡, David Held‡
@INPROCEEDINGS{wang-2025-ArticuBot,
title={{ArticuBot: Learning Universal Articulated Object Manipulation Policy via Large Scale Simulation}},
author={Wang, Yufei and Wang, Ziyu and Nakura, Mino and Bhowal, Pratik and Kuo, Chia-Liang and Chen, Yi-Ting and Erickson, Zackory and Held, David},
BOOKTITLE={Proceedings of Robotics: Science and Systems (RSS)},
year={2025}
}
This paper presents ArticuBot, in which a single learned policy enables a robotics system to open diverse categories of unseen articulated objects in the real world. This task has long been challenging for robotics due to the large variations in the geometry, size, and articulation types of such objects. Our system, Articubot, consists of three parts: generating a large number of demonstrations in physics-based simulation, distilling all generated demonstrations into a point cloud-based neural policy via imitation learning, and performing zero-shot sim2real transfer to real robotics systems. Utilizing sampling-based grasping and motion planning, our demonstration generalization pipeline is fast and effective, generating a total of 42.3k demonstrations over 322 training articulated objects. For policy learning, we propose a novel hierarchical policy representation, in which the high-level policy learns the sub-goal for the end-effector, and the low-level policy learns how to move the end-effector conditioned on the predicted goal. We demonstrate that this hierarchical approach achieves much better object-level generalization compared to the non-hierarchical version. We further propose a novel weighted displacement model for the high-level policy that grounds the prediction into the existing 3D structure of the scene, outperforming alternative policy representations. We show that our learned policy can zero-shot transfer to three different real robot settings: a fixed table-top Franka arm across two different labs, and an X-Arm on a mobile base, opening multiple unseen articulated objects across two labs, real lounges, and kitchens.
Robotics: Science and Systems (RSS), 2025
|
|
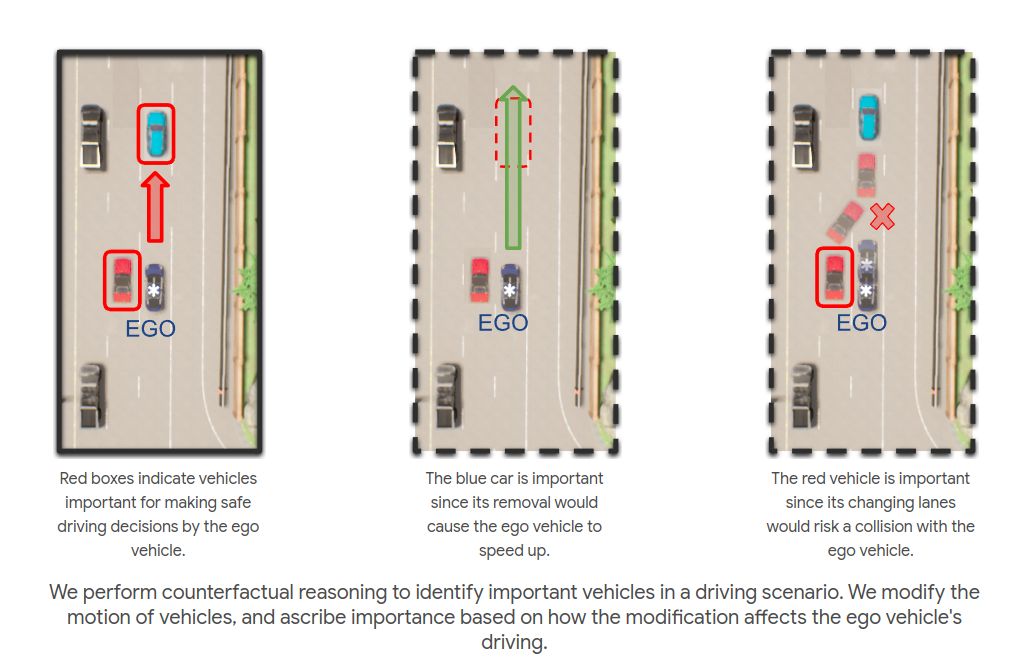
Object Importance Estimation using Counterfactual Reasoning for Intelligent Driving
Pranay Gupta, Abhijat Biswas, Henny Admoni, David Held
@article{gupta2024object,
title={Object Importance Estimation using Counterfactual Reasoning for Intelligent Driving},
author={Gupta, Pranay and Biswas, Abhijat and Admoni, Henny and Held, David},
journal={IEEE Robotics and Automation Letters},
year={2024}
}
The ability to identify important objects in a complex and dynamic driving environment is essential for autonomous driving agents to make safe and efficient driving decisions. It also helps assistive driving systems decide when to alert drivers. We tackle object importance estimation in a data-driven fashion and introduce HOIST - Human-annotated Object Importance in Simulated Traffic. HOIST contains driving scenarios with human-annotated importance labels for vehicles and pedestrians. We additionally propose a novel approach that relies on counterfactual reasoning to estimate an object's importance. We generate counterfactual scenarios by modifying the motion of objects and ascribe importance based on how the modifications affect the ego vehicle's driving. Our approach outperforms strong baselines for the task of object importance estimation on HOIST. We also perform ablation studies to justify our design choices and show the significance of the different components of our proposed approach.
Robotics and Automation Letters (RAL), 2024 with presentation at the International Conference on Robotics and Automation (ICRA), 2025
|

|
SplatSim: Zero-Shot Sim2Real Transfer of RGB Manipulation Policies Using Gaussian Splatting
M. Nomaan Qureshi, Sparsh Garg, Francisco Yandun, David Held, George Kantor, Abhisesh Silwal
@inproceedings{qureshi2024splatsimzeroshotsim2realtransfer,
title={SplatSim: Zero-Shot Sim2Real Transfer of RGB Manipulation Policies Using Gaussian Splatting},
author={M. Nomaan Qureshi, Sparsh Garg, Francisco Yandun, David Held, George Kantor, Abhisesh Silwal},
booktitle={IEEE International Conference on Robotics and Automation (ICRA)},
year={2025}
}
Sim2Real transfer, particularly for manipulation policies relying on RGB images, remains a critical challenge in robotics due to the significant domain shift between synthetic and real-world visual data. In this paper, we propose SplatSim, a novel framework that leverages Gaussian Splatting as the primary rendering primitive to reduce the Sim2Real gap for RGB-based manipulation policies. By replacing traditional mesh representations with Gaussian Splats in simulators, SplatSim produces highly photorealistic synthetic data while maintaining the scalability and cost-efficiency of simulation. We demonstrate the effectiveness of our framework by training manipulation policies within SplatSim and deploying them in the real world in a zero-shot manner, achieving an average success rate of 86.25%, compared to 97.5% for policies trained on real-world data.
IEEE International Conference on Robotics and Automation (ICRA), 2025
|
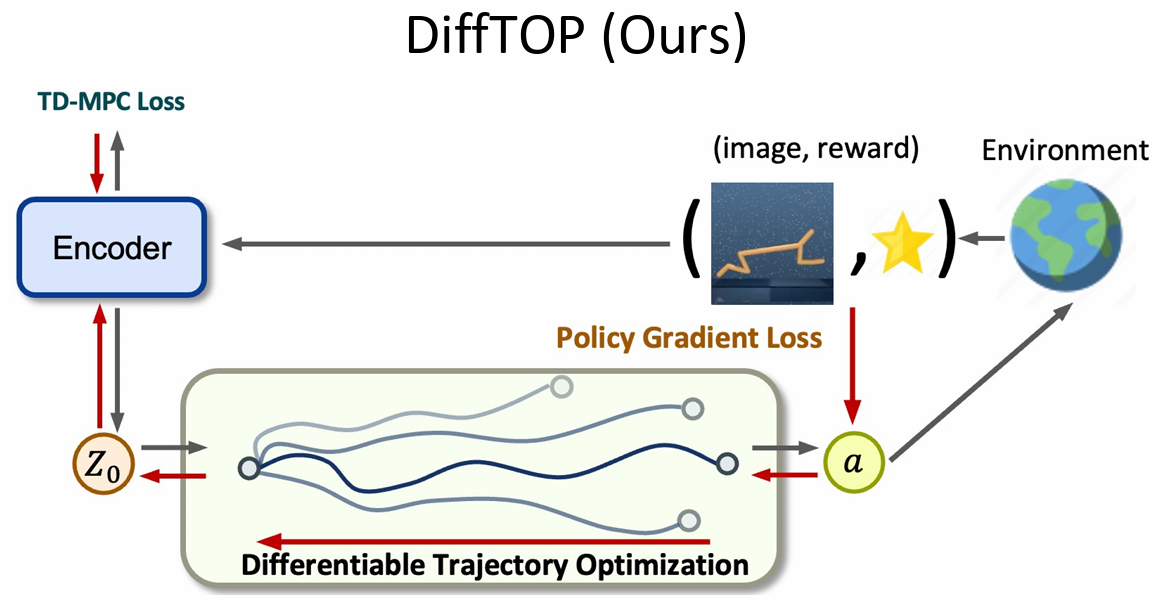
|
DiffTOP: Differentiable Trajectory Optimization for Deep Reinforcement and Imitation Learning
Weikang Wan*, Ziyu Wang*, Yufei Wang*, Zackory Erickson, David Held
@inproceedings{wan2024difftop,
title={DiffTOP: Differentiable Trajectory Optimization for Deep Reinforcement and Imitation Learning},
author={Wan, Weikang and Wang, Ziyu and Wang, Yufei and Erickson, Zackory and Held, David},
booktitle={Advances in neural information processing systems (NeurIPS)},
year={2024}
}
This paper introduces DiffTOP, which utilizes Differentiable Trajectory OPtimization as the policy representation to generate actions for deep reinforcement and imitation learning. Trajectory optimization is a powerful and widely used algorithm in control, parameterized by a cost and a dynamics function. The key to our approach is to leverage the recent progress in differentiable trajectory optimization, which enables computing the gradients of the loss with respect to the parameters of trajectory optimization. As a result, the cost and dynamics functions of trajectory optimization can be learned end-to-end. DiffTOP addresses the ``objective mismatch'' issue of prior model-based RL algorithms, as the dynamics model in DiffTOP is learned to directly maximize task performance by differentiating the policy gradient loss through the trajectory optimization process. We further benchmark DiffTOP for imitation learning on standard robotic manipulation task suites with high-dimensional sensory observations and compare our method to feed-forward policy classes as well as Energy-Based Models (EBM) and Diffusion. Across 15 model-based RL tasks and 35imitation learning tasks with high-dimensional image and point cloud inputs, DiffTOP outperforms prior state-of-the-art methods in both domains.
Advances in neural information processing systems (NeurIPS), 2024 - Spotlight Presentation
|

|
Non-rigid Relative Placement through 3D Dense Diffusion
Eric Cai, Octavian Donca, Ben Eisner, David Held
@inproceedings{cai2024tax3d,
title={Non-rigid Relative Placement through 3D Dense Diffusion},
author={Cai, Eric and Donca, Octavian and Eisner, Ben and Held, David},
booktitle={Conference on Robot Learning (CoRL)},
year={2024}
}
The task of "relative placement" is to predict the placement of one object in relation to another, e.g. placing a mug onto a mug rack. Through explicit object-centric geometric reasoning, recent methods for relative placement have made tremendous progress towards data-efficient learning for robot manipulation while generalizing to unseen task variations. However, they have yet to represent deformable transformations, despite the ubiquity of non-rigid bodies in real world settings. As a first step towards bridging this gap, we propose "cross-displacement" - an extension of the principles of relative placement to geometric relationships between deformable objects - and present a novel vision-based method to learn cross-displacement through dense diffusion. To this end, we demonstrate our method's ability to generalize to unseen object instances, out-of-distribution scene configurations, and multimodal goals on multiple highly deformable tasks (both in simulation and in the real world) beyond the scope of prior works.
Conference on Robot Learning (CoRL), 2024
|

|
FlowBotHD: History-Aware Diffuser Handling Ambiguities in Articulated Objects Manipulation
Yishu Li*, Wen Hui Leng*, Yiming Fang*, Ben Eisner, David Held;
@inproceedings{liflowbothd,
title={FlowBotHD: History-Aware Diffuser Handling Ambiguities in Articulated Objects Manipulation},
author={Li, Yishu and Leng, Wen Hui and Fang, Yiming and Eisner, Ben and Held, David},
booktitle={8th Annual Conference on Robot Learning}
}
We introduce a novel approach for manipulating articulated objects which are visually ambiguous, such doors which are symmetric or which are heavily occluded. These ambiguities can cause uncertainty over different possible articulation modes: for instance, when the articulation direction (e.g. push, pull, slide) or location (e.g. left side, right side) of a fully closed door are uncertain, or when distinguishing features like the plane of the door are occluded due to the viewing angle. To tackle these challenges, we propose a history-aware diffusion network that can model multi-modal distributions over articulation modes for articulated objects; our method further uses observation history to distinguish between modes and make stable predictions under occlusions. Experiments and analysis demonstrate that our method achieves state-of-art performance on articulated object manipulation and dramatically improves performance for articulated objects containing visual ambiguities.
Conference on Robot Learning (CoRL), 2024
|
![]()
|
Modeling Drivers' Situational Awareness from Eye Gaze for Driving Assistance
Abhijat Biswas, Pranay Gupta, Shreeya Khurana, David Held, Henny Admoni;
Conference on Robot Learning (CoRL), 2024
|
![]()
|
Visual Manipulation with Legs
Xialin He, Chengjing Yuan, Wenxuan Zhou, Ruihan Yang, David Held, Xiaolong Wang;
Conference on Robot Learning (CoRL), 2024
|
![]()
|
Unfolding the Literature: A Review of Robotic Cloth Manipulation
Alberta Longhini, Yufei Wang, Irene Garcia-Camacho, David Blanco-Mulero, Marco Moletta, Michael Welle, Guillem Alenyà, Hang Yin, Zackory Erickson, David Held, Júlia Borràs, Danica Kragic;
Annual Review of Control, Robotics, and Autonomous Systems, 2024
|
![]()
|
Active Velocity Estimation using Light Curtains via Self-Supervised Multi-Armed Bandits
Siddharth Ancha, Gaurav Pathak, Ji Zhang, Srinivasa Narasimhan, David Held;
Autonomous Robots, 2024
|

|
Learning Generalizable Tool-use Skills through Trajectory Generation
Carl Qi*, Yilin Wu*, Lifan Yu, Haoyue Liu, Bowen Jiang, Xingyu Lin†, David Held†
International Conference on Intelligent Robots and Systems (IROS), 2024
|

|
HACMan++: Spatially-Grounded Motion Primitives for Manipulation
Bowen Jiang*, Yilin Wu*, Wenxuan Zhou, Chris Paxton, David Held
@INPROCEEDINGS{Jiang-RSS-24,
AUTHOR = {Bowen Jiang AND Yilin Wu AND Wenxuan Zhou AND Chris Paxton AND David Held},
TITLE = {{HACMan++: Spatially-Grounded Motion Primitives for Manipulation}},
BOOKTITLE = {Proceedings of Robotics: Science and Systems},
YEAR = {2024},
ADDRESS = {Delft, Netherlands},
MONTH = {July},
DOI = {10.15607/RSS.2024.XX.129}
}
We present HACMan++, a reinforcement learning framework using a novel action space of spatially-grounded parameterized motion primitives for manipulation tasks.
Robotics: Science and Systems (RSS), 2024
|

|
RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation
Yufei Wang*, Zhou Xian*, Feng Chen*, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, Chuang Gan
@inproceedings{wang2024robogen,
title={RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation},
author={Wang, Yufei and Zhou, Xian and Chen, Feng and Wang, Tsun-Hsuan and Wang, Yian and Fragkiadaki, Katerina and Erickson, Zackory and Held, David and Gan, Chuang},
booktitle={International Conference on Machine Learning (ICML)},
year={2024}
}
We present RoboGen, a generative robotic agent that automatically learns diverse robotic skills at scale via generative simulation. RoboGen leverages the latest advancements in foundation and generative models. Instead of directly using or adapting these models to produce policies or low-level actions, we advocate for a generative scheme, which uses these models to automatically generate diversified tasks, scenes, and training supervisions, thereby scaling up robotic skill learning with minimal human supervision. Our approach equips a robotic agent with a self-guided propose-generate-learn cycle: the agent first proposes interesting tasks and skills to develop, and then generates corresponding simulation environments by populating pertinent objects and assets with proper spatial configurations. Afterwards, the agent decomposes the proposed high-level task into sub-tasks, selects the optimal learning approach (reinforcement learning, motion planning, or trajectory optimization), generates required training supervision, and then learns policies to acquire the proposed skill. Our work attempts to extract the extensive and versatile knowledge embedded in large-scale models and transfer them to the field of robotics. Our fully generative pipeline can be queried repeatedly, producing an endless stream of skill demonstrations associated with diverse tasks and environments.
International Conference on Machine Learning (ICML), 2024
|
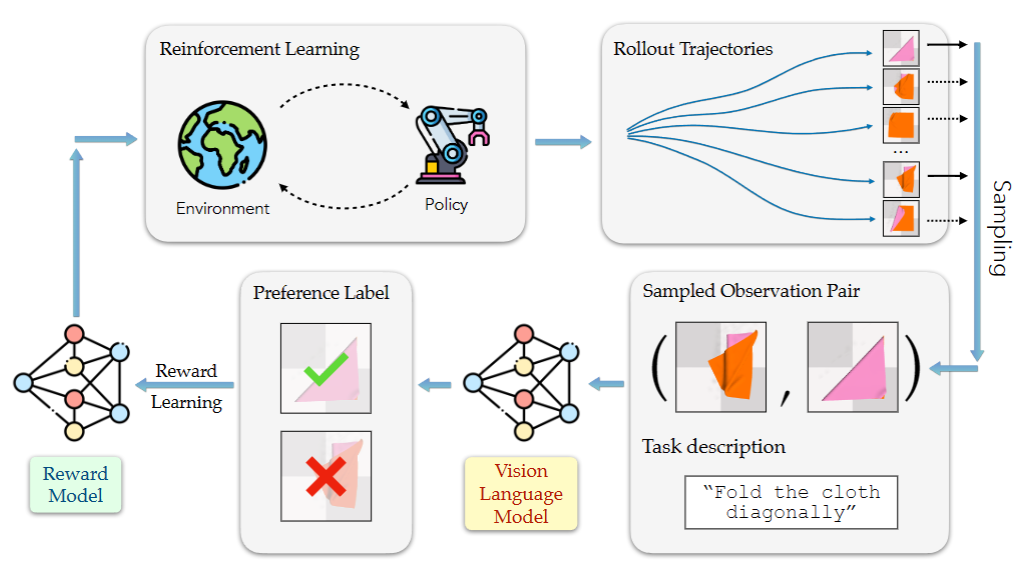
|
RL-VLM-F: Reinforcement Learning from Vision Language Foundation Model Feedback
Yufei Wang*, Zhanyi Sun*, Jesse Zhang, Zhou Xian, Erdem Bıyık, David Held†, Zackory Erickson†
@inproceedings{wang2024rlvlmf,
title={RL-VLM-F: Reinforcement Learning from Vision Language Foundation Model Feedback},
author={Wang, Yufei and Sun, Zhanyi and Zhang, Jesse and Xian, Zhou and Biyik, Erdem and Held, David and Erickson, Zackory},
booktitle={International Conference on Machine Learning (ICML)},
year={2024}
}
Reward engineering has long been a challenge in Reinforcement Learning research, as it often requires extensive human effort. In this paper, we propose RL-VLM-F, a method that automatically generates reward functions for agents to learn new tasks, using only a text description of the task goal and the agent’s visual observations, by leveraging feedback from vision language foundation models (VLMs). The key to our approach is to query these models to give preferences over pairs of the agent’s image observations based on the text description of the task goal, and then learn a reward function from the preference labels. We demonstrate that RL-VLM-F successfully produces effective rewards and policies across various domains — including classic control, as well as manipulation of rigid, articulated, and deformable objects — without the need for human supervision, outperforming prior methods that use large pretrained models for reward generation under the same assumptions.
International Conference on Machine Learning (ICML), 2024
|
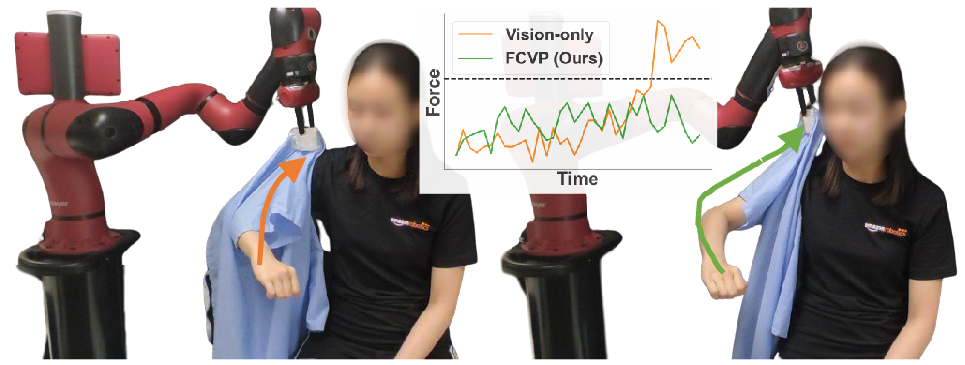
|
Force Constrained Visual Policy: Safe Robot-Assisted Dressing via Multi-Modal Sensing
Zhanyi Sun*, Yufei Wang*, David Held†, Zackory Erickson†
@article{sun2024force,
title={Force-Constrained Visual Policy: Safe Robot-Assisted Dressing via Multi-Modal Sensing},
author={Sun, Zhanyi and Wang, Yufei and Held, David and Erickson, Zackory},
journal={IEEE Robotics and Automation Letters},
year={2024}
}
Robot-assisted dressing could profoundly enhance the quality of life of adults with physical disabilities. To achieve this, a robot can benefit from both visual and force sensing. The former enables the robot to ascertain human body pose and garment deformations, while the latter helps maintain safety and comfort during the dressing process. In this paper, we introduce a new technique that leverages both vision and force modalities for this assistive task. Our approach first trains a vision-based dressing policy using reinforcement learning in simulation with varying body sizes, poses, and types of garments. We then learn a force dynamics model for action planning to ensure safety. Due to limitations of simulating accurate force data when deformable garments interact with the human body, we learn a force dynamics model directly from real-world data. Our proposed method combines the vision-based policy, trained in simulation, with the force dynamics model, learned in the real world, by solving a constrained optimization problem to infer actions that facilitate the dressing process without applying excessive force on the person. We evaluate our system in simulation and in a real-world human study with 10 participants across 240 dressing trials, showing it greatly outperforms prior baselines. Video demonstrations are available on our project website.
Robotics and Automation Letters (RAL), 2024
|
|
Deep SE(3)-Equivariant Geometric Reasoning for Precise Placement Tasks
Ben Eisner, Yi Yang, Todor Davchev, Mel Vecerik, Jonathan Scholz, David Held
@article{eisner2024deep,
title={Deep {SE}(3)-Equivariant Geometric Reasoning for Precise Placement Tasks},
author={Ben Eisner and Yi Yang and Todor Davchev and Mel Vecerik and Jonathan Scholz and David Held},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=2inBuwTyL2}
}
Many robot manipulation tasks can be framed as geometric reasoning tasks, where an agent must be able to precisely manipulate an object into a position that satisfies the task from a set of initial conditions. Often, task success is defined based on the relationship between two objects - for instance, hanging a mug on a rack. In such cases, the solution should be equivariant to the initial position of the objects as well as the agent, and invariant to the pose of the camera. This poses a challenge for learning systems which attempt to solve this task by learning directly from high-dimensional demonstrations - the agent must learn to be both equivariant as well as precise, which can be challenging without any inductive biases about the problem. In this work, we propose a method for precise relative pose prediction which is provably SE(3)-equivariant, can be learned from only a few demonstrations, and can generalize across variations in a class of objects. We accomplish this by factoring the problem into learning an SE(3) invariant task-specific representation of the scene and then interpreting this representation with novel geometric reasoning layers which are provably SE(3) equivariant. We demonstrate that our method can yield substantially more precise placement predictions in simulated placement tasks than previous methods trained with the same amount of data, and can accurately represent relative placement relationships data collected from real-world demonstrations.
International Conference on Learning Representations (ICLR), 2024
|

|
Reinforcement Learning in a Safety-Embedded MDP with Trajectory Optimization
Fan Yang, Wenxuan Zhou, Zuxin Liu, Ding Zhao, David Held
@article{yang2023reinforcement,
title={Reinforcement Learning in a Safety-Embedded MDP with Trajectory Optimization},
author={Yang, Fan and Zhou, Wenxuan and Liu, Zuxin and Zhao, Ding and Held, David},
journal={arXiv preprint arXiv:2310.06903},
year={2023}
}
Safe Reinforcement Learning (RL) plays an important role in applying RL algorithms to safety-critical real-world applications, addressing the trade-off between maximizing rewards and adhering to safety constraints. This work introduces a novel approach that combines RL with trajectory optimization to manage this trade-off effectively. Our approach embeds safety constraints within the action space of a modified Markov Decision Process (MDP). The RL agent produces a sequence of actions that are transformed into safe trajectories by a trajectory optimizer, thereby effectively ensuring safety and increasing training stability. This novel approach excels in its performance on challenging Safety Gym tasks, achieving significantly higher rewards and near-zero safety violations during inference. The method's real-world applicability is demonstrated through a safe and effective deployment in a real robot task of box-pushing around obstacles.
International Conference on Robotics and Automation (ICRA), 2024
|
|
Learning Distributional Demonstration Spaces for Task-Specific Cross-Pose Estimation
Jenny Wang*, Octavian Donca*, David Held
@article{wang2024taxposed,
title={Learning Distributional Demonstration Spaces for Task-Specific Cross-Pose Estimation},
author={Wang, Jenny and Donca, Octavian and Held, David},
journal={IEEE International Conference on Robotics and Automation (ICRA), 2024},
year={2024}
}
Relative placement tasks are an important category of tasks in which one object needs to be placed in a desired pose relative to another object. Previous work has shown success in learning relative placement tasks from just a small number of demonstrations, when using relational reasoning networks with geometric inductive biases. However, such methods fail to consider that demonstrations for the same task can be fundamentally multimodal, like a mug hanging on any of n racks. We propose a method that retains the provably translation-invariant and relational properties of prior work but incorporates additional properties that account for multimodal, distributional examples. We show that our method is able to learn precise relative placement tasks with a small number of multimodal demonstrations with no human annotations across a diverse set of objects within a category.
International Conference on Robotics and Automation (ICRA), 2024
|

|
FlowBot++: Learning Generalized Articulated Objects Manipulation via Articulation Projections
Harry Zhang, Ben Eisner, David Held
@inproceedings{zhang2023fbpp,
title={FlowBot++: Learning Generalized Articulated Objects Manipulation via Articulation Projection},
author={Zhang, Harry and Eisner, Ben and Held, David},
journal={Conference on Robot Learning (CoRL)},
year={2023}
}
Understanding and manipulating articulated objects, such as doors and drawers, is crucial for robots operating in human environments. We wish to develop a system that can learn to articulate novel objects with no prior interaction, after training on other articulated objects. Previous approaches for articulated object manipulation rely on either modular methods which are brittle or end-to-end methods, which lack generalizability. This paper presents FlowBot++, a deep 3D vision-based robotic system that predicts dense per-point motion and dense articulation parameters of articulated objects to assist in downstream manipulation tasks. FlowBot++ introduces a novel per-point representation of the articulated motion and articulation parameters that are combined to produce a more accurate estimate than either method on their own. Simulated experiments on the PartNet-Mobility dataset validate the performance of our system in articulating a wide range of objects, while real-world experiments on real objects' point clouds and a Sawyer robot demonstrate the generalizability and feasibility of our system in real-world scenarios.
Conference on Robot Learning (CoRL), 2023
|

|
HACMan: Learning Hybrid Actor-Critic Maps for 6D Non-Prehensile Manipulation
Wenxuan Zhou, Bowen Jiang, Fan Yang, Chris Paxton*, David Held*
@inproceedings{zhou2023hacman,
title={HACMan: Learning Hybrid Actor-Critic Maps for 6D Non-Prehensile Manipulation},
author={Zhou, Wenxuan and Jiang, Bowen and Yang, Fan and Paxton, Chris and Held, David},
journal={Conference on Robot Learning (CoRL)},
year={2023},
}
Manipulating objects without grasping them is an essential component of human dexterity, referred to as non-prehensile manipulation. Non-prehensile manipulation may enable more complex interactions with the objects, but also presents challenges in reasoning about gripper-object interactions. In this work, we introduce Hybrid Actor-Critic Maps for Manipulation (HACMan), a reinforcement learning approach for 6D non-prehensile manipulation of objects using point cloud observations. HACMan proposes a temporally-abstracted and spatially-grounded object-centric action representation that consists of selecting a contact location from the object point cloud and a set of motion parameters describing how the robot will move after making contact. We modify an existing off-policy RL algorithm to learn in this hybrid discrete-continuous action representation. We evaluate HACMan on a 6D object pose alignment task in both simulation and in the real world. On the hardest version of our task, with randomized initial poses, randomized 6D goals, and diverse object categories, our policy demonstrates strong generalization to unseen object categories without a performance drop, achieving an 89% success rate on unseen objects in simulation and 50% success rate with zero-shot transfer in the real world. Compared to alternative action representations, HACMan achieves a success rate more than three times higher than the best baseline. With zero-shot sim2real transfer, our policy can successfully manipulate unseen objects in the real world for challenging non-planar goals, using dynamic and contact-rich non-prehensile skills.
Conference on Robot Learning (CoRL), 2023 - Oral Presentation (Selection rate 6.6%)
|

|
Bagging by Learning to Singulate Layers Using Interactive Perception
Lawrence Yunliang Chen, Baiyu Shi, Roy Lin, Daniel Seita, Ayah Ahmad, Richard Cheng, Thomas Kollar, David Held, Ken Goldberg
@inproceedings{slipbagging2023,\n
title={{Bagging by Learning to Singulate Layers Using Interactive Perception}},\n
author={Lawrence Yunliang Chen and Baiyu Shi and Roy Lin and Daniel Seita and Ayah Ahmad and Richard Cheng and Thomas Kollar and David Held and Ken Goldberg},\n
booktitle={IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},\n
year={2023}\n}"
Many fabric handling and 2D deformable material tasks in homes and industry require singulating layers of material such as opening a bag or arranging garments for sewing. In contrast to methods requiring specialized sensing or end effectors, we use only visual observations with ordinary parallel jaw grippers. We propose SLIP, Singulating Layers using Interactive Perception, and apply SLIP to the task of autonomous bagging. We develop SLIP-Bagging, a bagging algorithm that manipulates a plastic or fabric bag from an unstructured state, and uses SLIP to grasp the top layer of the bag to open it for object insertion. In physical experiments, a YuMi robot achieves a success rate of 67% to 81% across bags of a variety of materials, shapes, and sizes, significantly improving in success rate and generality over prior work. Experiments also suggest that SLIP can be applied to tasks such as singulating layers of folded cloth and garments.
International Conference on Intelligent Robots and Systems (IROS), 2023
|

|
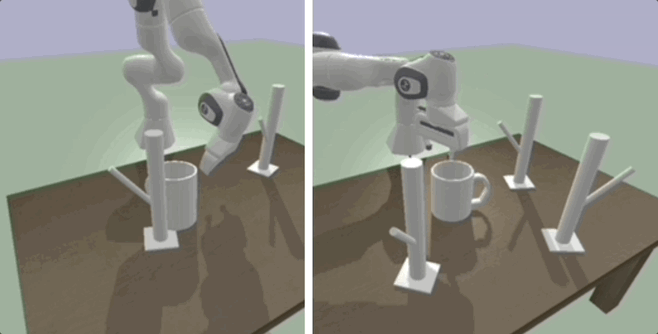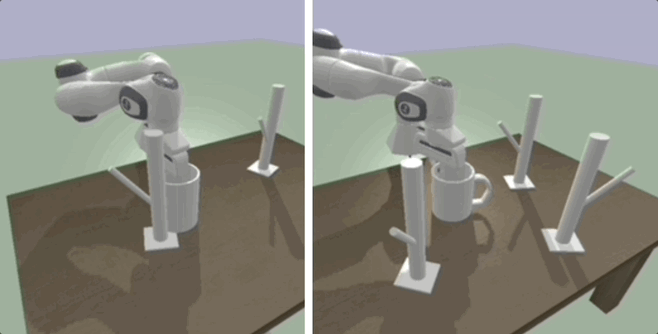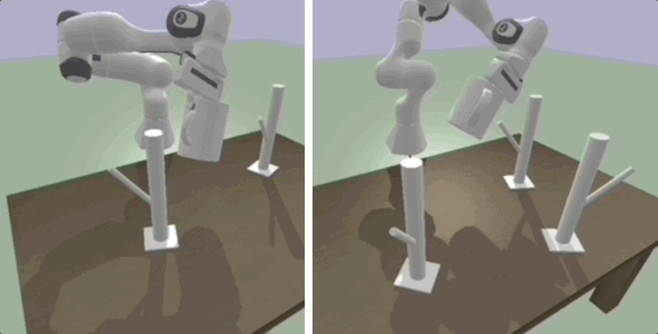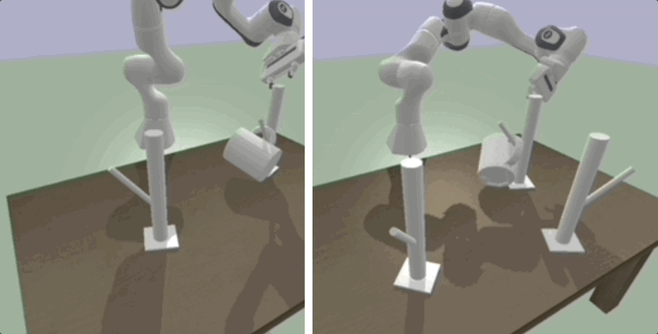
One Policy to Dress Them All: Learning to Dress People with Diverse Poses and Garments
Yufei Wang, Zhanyi Sun, Zackory Erickson*, David Held*
@inproceedings{Wang2023One,\n title={One Policy to Dress Them All: Learning to Dress People with Diverse Poses and Garments},\n author={Wang, Yufei and Sun, Zhanyi and Erickson, Zackory and Held, David},\n booktitle={Robotics: Science\ \ and Systems (RSS)},\n year={2023}\n }"
Robot-assisted dressing could benefit the lives of many people such as older adults and individuals with disabilities. Despite such potential, robot-assisted dressing remains a challenging task for robotics as it involves complex manipulation of deformable cloth in 3D space. Many prior works aim to solve the robot-assisted dressing task, but they make certain assumptions such as a fixed garment and a fixed arm pose that limit their ability to generalize. In this work, we develop a robot-assisted dressing system that is able to dress different garments on people with diverse poses from partial point cloud observations, based on a learned policy. We show that with proper design of the policy architecture and Q function, reinforcement learning (RL) can be used to learn effective policies with partial point cloud observations that work well for dressing diverse garments. We further leverage policy distillation to combine multiple policies trained on different ranges of human arm poses into a single policy that works over a wide range of different arm poses. We conduct comprehensive real-world evaluations of our system with 510 dressing trials in a human study with 17 participants with different arm poses and dressed garments. Our system is able to dress 86\% of the length of the participants arms on average. Videos can be found on the anonymized project webpage: https://sites.google.com/view/one-policy-dress.
Robotics: Science and Systems (RSS), 2023
|
|
Active Velocity Estimation using Light Curtains via Self-Supervised Multi-Armed Bandits
Siddharth Ancha, Gaurav Pathak, Ji Zhang, Srinivasa Narasimhan, David Held
@inproceedings{ancha2023rss,\n
title = {Active Velocity Estimation using Light Curtains via Self-Supervised Multi-Armed Bandits},\n
author = {Siddharth Ancha AND Gaurav Pathak AND Ji Zhang AND Srinivasa Narasimhan AND David Held},\n
booktitle = {Proceedings of Robotics: Science and Systems},\n
year = {2023},\n
\ address = {Daegu, Republic of Korea},\n \ month = {July},\n
}
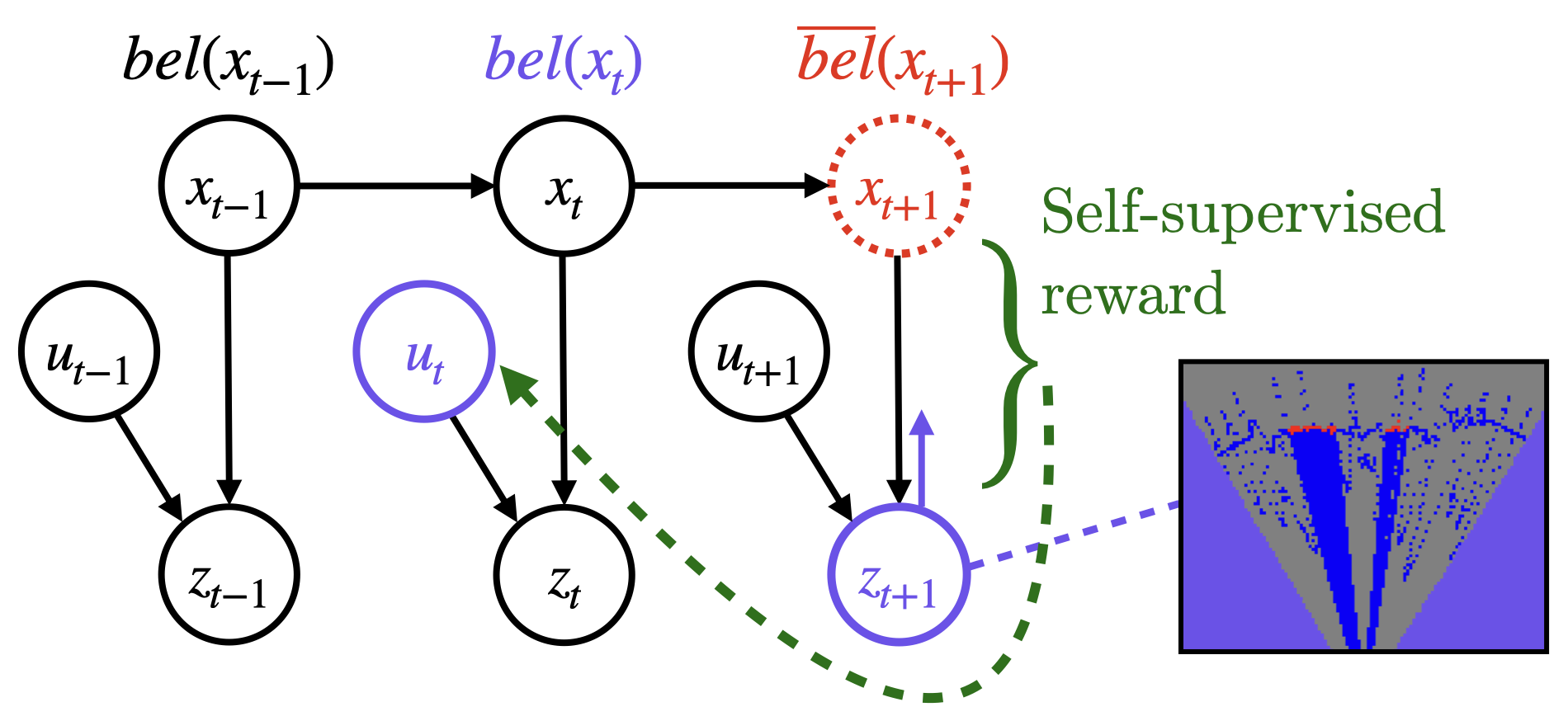
To navigate in an environment safely and autonomously, robots must accurately estimate where obstacles are and how they move. Instead of using expensive traditional 3D sensors, we explore the use of a much cheaper, faster, and higher resolution alternative: programmable light curtains. Light curtains are a controllable depth sensor that sense only along a surface that the user selects. We adapt a probabilistic method based on particle filters and occupancy grids to explicitly estimate the position and velocity of 3D points in the scene using partial measurements made by light curtains. The central challenge is to decide where to place the light curtain to accurately perform this task. We propose multiple curtain placement strategies guided by maximizing information gain and verifying predicted object locations. Then, we combine these strategies using an online learning framework. We propose a novel self-supervised reward function that evaluates the accuracy of current velocity estimates using future light curtain placements. We use a multi-armed bandit framework to intelligently switch between placement policies in real time, outperforming fixed policies. We develop a full-stack navigation system that uses position and velocity estimates from light curtains for downstream tasks such as localization, mapping, path-planning, and obstacle avoidance. This work paves the way for controllable light curtains to accurately, efficiently, and purposefully perceive and navigate complex and dynamic environments.
Robotics: Science and Systems (RSS), 2023
|

|
Point Cloud Forecasting as a Proxy for 4D Occupancy Forecasting
Tarasha Khurana, Peiyun Hu, David Held, Deva Ramanan
@inproceedings{Khurana2023point,\n
title={Point Cloud Forecasting as a Proxy for 4D Occupancy Forecasting},\n
author={Khurana, Tarasha and Hu, Peiyun and Held, David and Ramanan, Deva},\n
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and\
\ Pattern Recognition (CVPR)},\n
year={2023}\n
}
Predicting how the world can evolve in the future is crucial for motion planning in autonomous systems. Classical methods are limited because they rely on costly human annotations in the form of semantic class labels, bounding boxes, and tracks or HD maps of cities to plan their motion — and thus are difficult to scale to large unlabeled datasets. One promising self-supervised task is 3D point cloud forecasting from unannotated LiDAR sequences. We show that this task requires algorithms to implicitly capture (1) sensor extrinsics (i.e., the egomotion of the autonomous vehicle), (2) sensor intrinsics (i.e., the sampling pattern specific to the particular LiDAR sensor), and (3) the shape and motion of other objects in the scene. But autonomous systems should make predictions about the world and not their sensors! To this end, we factor out (1) and (2) by recasting the task as one of spacetime (4D) occupancy forecasting. But because it is expensive to obtain ground-truth 4D occupancy, we “render” point cloud data from 4D occupancy predictions given sensor extrinsics and intrinsics, allowing one to train and test occupancy algorithms with unannotated LiDAR sequences. This also allows one to evaluate and compare point cloud forecasting algorithms across diverse datasets, sensors, and vehicles.
Conference on Computer Vision and Pattern Recognition (CVPR), 2023
|
|
Elastic Context: Encoding Elasticity for Data-driven Models of Textiles
Alberta Longhini, Marco Moletta, Alfredo Reichlin, Michael C. Welle, Alexander Kravberg, Yufei Wang, David Held, Zackory Erickson, Danica Kragic
@inproceedings{Longhini2023elastic,\n
title={Elastic Context: Encoding Elasticity for Data-driven Models of Textiles },\n
author={Longhini, Alberta and Moletta, Marco and Reichlin, Alfredo and Welle, Michael C. and Kravberg, Alexander and Wang, Yufei and Held, David and Erickson, Zackory and Kragic, Danica },\n
booktitle={IEEE International Conference on Robotics and Automation (ICRA), 2023},\n
year={2023}\n
}
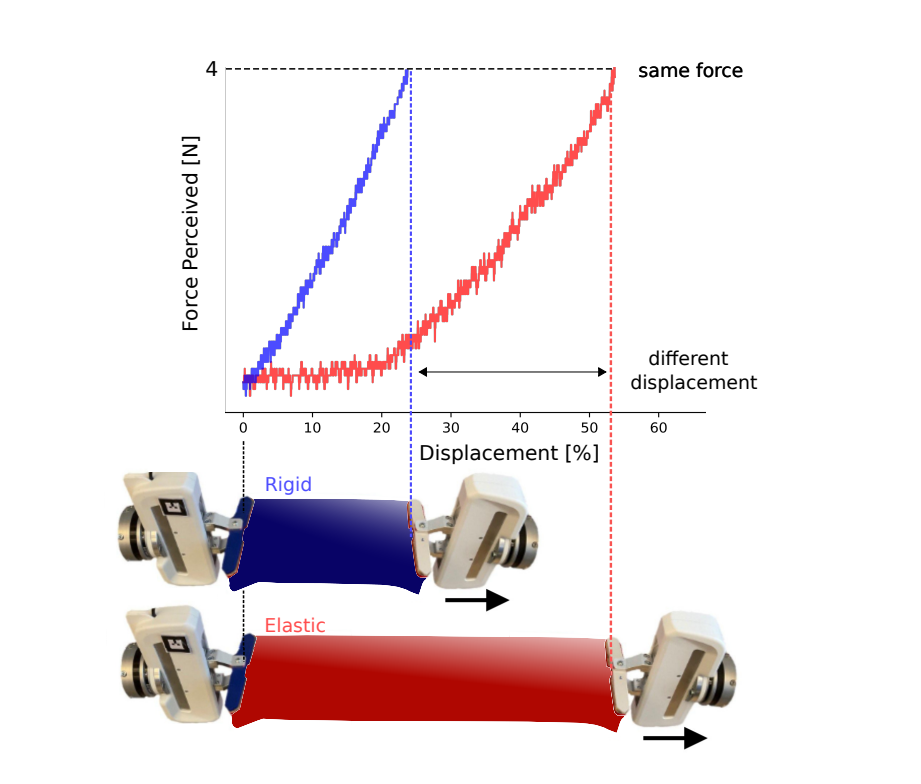
Physical interaction with textiles, such as assistive dressing, relies on advanced dextreous capabilities. The underlying complexity in textile behavior when being pulled and stretched, is due to both the yarn material properties and the textile construction technique. Today, there are no commonly adopted and annotated datasets on which the various interaction or property identification methods are assessed. One important property that affects the interaction is material elasticity that results from both the yarn material and construction technique: these two are intertwined and, if not known a-priori, almost impossible to identify through sensing commonly available on robotic platforms. We introduce Elastic Context (EC), a concept that integrates various properties that affect elastic behavior, to enable a more effective physical interaction with textiles. The definition of EC relies on stress/strain curves commonly used in textile engineering, which we reformulated for robotic applications. We employ EC using Graph Neural Network (GNN) to learn generalized elastic behaviors of textiles. Furthermore, we explore the effect the dimension of the EC has on accurate force modeling of non-linear real-world elastic behaviors, highlighting the challenges of current robotic setups to sense textile properties.
International Conference on Robotics and Automation (ICRA), 2023
|

|
EDO-Net: Learning Elastic Properties of Deformable Objects from Graph Dynamics
Alberta Longhini*, Marco Moletta*, Alfredo Reichlin, Michael C. Welle, David Held, Zackory Erickson, Danica Kragic
@inproceedings{Longhini2023EDO,
title={EDO-Net: Learning Elastic Properties of Deformable Objects from Graph Dynamics},
author={Longhini, Alberta and Moletta, Marco and Reichlin, Alfredo and Welle, Michael C. and Held, David and Erickson, Zackory and Kragic, Danica },
booktitle={IEEE International Conference on Robotics and Automation (ICRA), 2023},
year={2023}
}
We study the problem of learning graph dynamics of deformable objects which generalize to unknown physical properties. In particular, we leverage a latent representation of elastic physical properties of cloth-like deformable objects which we explore through a pulling interaction. We propose EDO-Net (Elastic Deformable Object - Net), a model trained in a self-supervised fashion on a large variety of samples with different elastic properties. EDO-Net jointly learns an adaptation module, responsible for extracting a latent representation of the physical properties of the object and a forward-dynamics module, which leverages the latent representation to predict future states of cloth-like objects, represented as graphs. We evaluate EDO-Net both in simulation and real world, assessing its capabilities of: 1) generalizing to unknown physical properties of cloth-like deformable objects, 2) transferring the learned representation to new downstream tasks.
International Conference on Robotics and Automation (ICRA), 2023
|

|
Self-supervised Cloth Reconstruction via Action-conditioned Cloth Tracking
Zixuan Huang, Xingyu Lin, David Held
@inproceedings{huang2023act,\n
title={Self-supervised Cloth Reconstruction via Action-conditioned Cloth Tracking},\n
author={Huang, Zixuan and Lin, Xingyu and Held, David},\n
booktitle={IEEE International Conference on Robotics and Automation (ICRA), 2023},\n
year={2023}\n
}
State estimation is one of the greatest challenges for cloth manipulation due to cloth's high dimensionality and self-occlusion. Prior works propose to identify the full state of crumpled clothes by training a mesh reconstruction model in simulation. However, such models are prone to suffer from a sim-to-real gap due to differences between cloth simulation and the real world. In this work, we propose a self-supervised method to finetune a mesh reconstruction model in the real world. Since the full mesh of crumpled cloth is difficult to obtain in the real world, we design a special data collection scheme and an action-conditioned model-based cloth tracking method to generate pseudo-labels for self-supervised learning. By finetuning the pretrained mesh reconstruction model on this pseudo-labeled dataset, we show that we can improve the quality of the reconstructed mesh without requiring human annotations, and improve the performance of downstream manipulation task.
International Conference on Robotics and Automation (ICRA), 2023
|

|
Neural Grasp Distance Fields for Robot Manipulation
Thomas Weng, David Held, Franziska Meier, Mustafa Mukadam
@article{weng2023ngdf,\n
title={Neural Grasp Distance Fields for Robot Manipulation},\n
author={Weng, Thomas and Held, David and Meier, Franziska and Mukadam, Mustafa},\n
booktitle={IEEE International Conference on Robotics and Automation (ICRA)},\n
year={2023}\n}"
We formulate grasp learning as a neural field and present Neural Grasp Distance Fields (NGDF). Here, the input is a 6D pose of a robot end effector and output is a distance to a continuous manifold of valid grasps for an object. In contrast to current approaches that predict a set of discrete candidate grasps, the distance-based NGDF representation is easily interpreted as a cost, and minimizing this cost produces a successful grasp pose. This grasp distance cost can be incorporated directly into a trajectory optimizer for joint optimization with other costs such as trajectory smoothness and collision avoidance. During optimization, as the various costs are balanced and minimized, the grasp target is allowed to smoothly vary, as the learned grasp field is continuous. In simulation benchmarks with a Franka arm, we find that joint grasping and planning with NGDF outperforms baselines by 63% execution success while generalizing to unseen query poses and unseen object shapes.
International Conference on Robotics and Automation (ICRA), 2023
|

|
AutoBag: Learning to Open Plastic Bags and Insert Objects
Lawrence Yunliang Chen, Baiyu Shi, Daniel Seita, Richard Cheng, Thomas Kollar, David Held, Ken Goldberg
@inproceedings{autobag2023,\n
title={{AutoBag: Learning to Open Plastic Bags and Insert Objects}},\n
author={Lawrence Yunliang Chen and Baiyu Shi and Daniel Seita and Richard Cheng and Thomas Kollar and David Held and Ken Goldberg},\n
booktitle={IEEE International Conference on Robotics and Automation (ICRA), 2023},\n
year={2023}\n}"
Thin plastic bags are ubiquitous in retail stores, healthcare, food handling, recycling, homes, and school lunchrooms. They are challenging both for perception (due to specularities and occlusions) and for manipulation (due to the dynamics of their 3D deformable structure). We formulate the task of manipulating common plastic shopping bags with two handles from an unstructured initial state to a state where solid objects can be inserted into the bag for transport. We propose a self-supervised learning framework where a dual-arm robot learns to recognize the handles and rim of plastic bags using UV-fluorescent markings; at execution time, the robot does not use UV markings or UV light. We propose Autonomous Bagging (AutoBag), where the robot uses the learned perception model to open plastic bags through iterative manipulation. We present novel metrics to evaluate the quality of a bag state and new motion primitives for reorienting and opening bags from visual observations. In physical experiments, a YuMi robot using AutoBag is able to open bags and achieve a success rate of 16/30 for inserting at least one item across a variety of initial bag configurations
International Conference on Robotics and Automation (ICRA), 2023
|

|
Learning to Grasp the Ungraspable with Emergent Extrinsic Dexterity
Wenxuan Zhou, David Held
@inproceedings{zhou2022ungraspable,\n
title={{Learning to Grasp the Ungraspable with Emergent Extrinsic Dexterity}},\n
author={Zhou, Wenxuan and Held, David},\n
booktitle={Conference on Robot Learning (CoRL)},\n
year={2022}\n
}
A simple gripper can solve more complex manipulation tasks if it can utilize the external environment such as pushing the object against the table or a vertical wall, known as "Extrinsic Dexterity." Previous work in extrinsic dexterity usually has careful assumptions about contacts which impose restrictions on robot design, robot motions, and the variations of the physical parameters. In this work, we develop a system based on reinforcement learning (RL) to address these limitations. We study the task of “Occluded Grasping” which aims to grasp the object in configurations that are initially occluded; the robot needs to move the object into a configuration from which these grasps can be achieved. We present a system with model-free RL that successfully achieves this task using a simple gripper with extrinsic dexterity. The policy learns emergent behaviors of pushing the object against the wall to rotate and then grasp it without additional reward terms on extrinsic dexterity. We discuss important components of the system including the design of the RL problem, multi-grasp training and selection, and policy generalization with automatic curriculum. Most importantly, the policy trained in simulation is zero-shot transferred to a physical robot. It demonstrates dynamic and contact-rich motions with a simple gripper that generalizes across objects with various size, density, surface friction, and shape with a 78% success rate.
Conference on Robot Learning (CoRL), 2022 - Oral Presentation (Selection rate 6.5%)
|

|
TAX-Pose: Task-Specific Cross-Pose Estimation for Robot Manipulation
Chuer Pan*, Brian Okorn*, Harry Zhang*, Ben Eisner*, David Held
@inproceedings{pan2022tax,\n
title={TAX-Pose: Task-Specific Cross-Pose Estimation for Robot Manipulation},\n
author={Pan, Chuer and Okorn, Brian and Zhang, Harry and Eisner, Ben and Held, David},\n
booktitle={Conference on Robot Learning (CoRL)},\n
year={2022}\n
}
How do we imbue robots with the ability to efficiently manipulate unseen objects and transfer relevant skills based on demonstrations? End-to-end learning methods often fail to generalize to novel objects or unseen configurations. Instead, we focus on the task-specific pose relationship between relevant parts of interacting objects. We conjecture that this relationship is a generalizable notion of a manipulation task that can transfer to new objects in the same category; examples include the relationship between the pose of a pan relative to an oven or the pose of a mug relative to a mug rack. We call this task-specific pose relationship “cross-pose” and provide a mathematical definition of this concept. We propose a vision-based system that learns to estimate the cross-pose between two objects for a given manipulation task using learned cross-object correspondences. The estimated cross-pose is then used to guide a downstream motion planner to manipulate the objects into the desired pose relationship (placing a pan into the oven or the mug onto the mug rack). We demonstrate our method’s capability to generalize to unseen objects, in some cases after training on only 10 demonstrations in the real world. Results show that our system achieves state-of-the-art performance in both simulated and real-world experiments across a number of tasks.
Conference on Robot Learning (CoRL), 2022
|

|
ToolFlowNet: Robotic Manipulation with Tools via Predicting Tool Flow from Point Clouds
Daniel Seita, Yufei Wang†, Sarthak J Shetty†, Edward Yao Li†, Zackory Erickson, David Held
Conference on Robot Learning (CoRL), 2022
|

|
Planning with Spatial-Temporal Abstraction from Point Clouds for Deformable Object Manipulation
Xingyu Lin*, Carl Qi*, Yunchu Zhang, Zhiao Huang, Katerina Fragkiadaki, Yunzhu Li, Chuang Gan, David Held
@inproceedings{\n \ lin2022planning,\n
title={Planning with Spatial-Temporal Abstraction from Point Clouds for Deformable Object Manipulation},\n
author={Xingyu Lin and Carl Qi and Yunchu Zhang and Yunzhu Li and Zhiao Huang and Katerina Fragkiadaki and Chuang Gan and David Held},\n
booktitle={6th Annual Conference on Robot Learning},\n
year={2022},\n
url={https://openreview.net/forum?id=tyxyBj2w4vw}\n
}
Effective planning of long-horizon deformable object manipulation requires suitable
abstractions at both the spatial and temporal levels.
Previous methods typically either focus on short-horizon tasks or make
strong assumptions that full-state information is available, which prevents
their use on deformable objects. In this paper, we propose PlAnning with
Spatial-Temporal Abstraction (PASTA), which incorporates both spatial abstraction
(reasoning about objects and their relations to each other) and temporal
abstraction (reasoning over skills instead of low-level actions). Our framework
maps high-dimension 3D observations such as point clouds into a set of latent
vectors and plans over skill sequences on top of the latent set representation.
We show that our method can effectively perform challenging sequential deformable
object manipulation tasks in the real world, which require combining multiple
tool-use skills such as cutting with a knife, pushing with a pusher, and spreading
dough with a roller.
Conference on Robot Learning (CoRL), 2022
|
|
Deep Projective Rotation Estimation through Relative Supervision
Brian Okorn*, Chuer Pan*, Martial Hebert, David Held
@inproceedings{okorndeep,\n
title={Deep Projective Rotation Estimation through Relative Supervision},\n
author={Okorn, Brian and Pan, Chuer and Hebert, Martial and Held, David},\n
booktitle={Conference on Robot Learning (CoRL)}\n
year={2022},\n
}
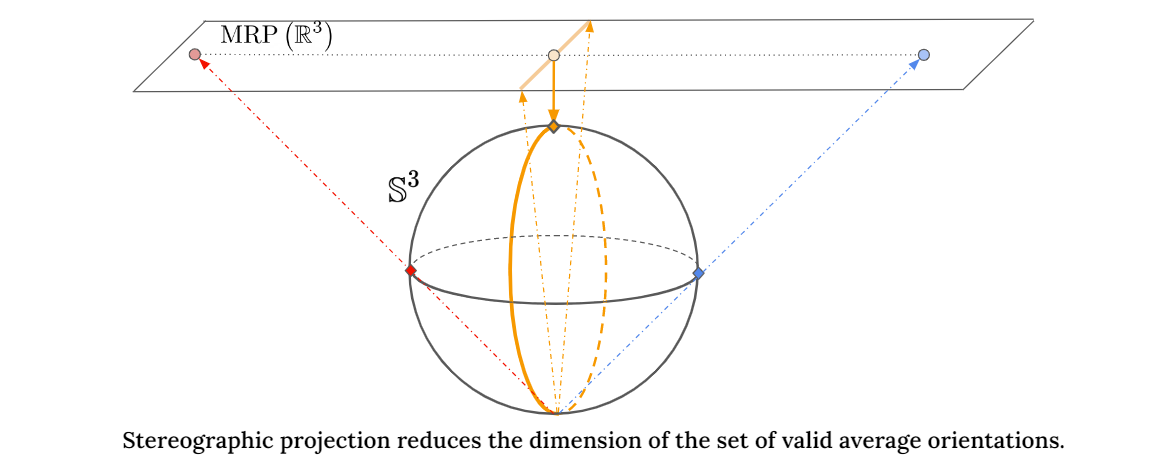
Orientation estimation is the core to a variety of vision and robotics tasks such as camera and object pose estimation. Deep learning has offered a way to develop image-based orientation estimators; however, such estimators often require training on a large labeled dataset, which can be time-intensive to collect. In this work, we explore whether self-supervised learning from unlabeled data can be used to alleviate this issue. Specifically, we assume access to estimates of the relative orientation between neighboring poses, such that can be obtained via a local alignment method. While self-supervised learning has been used successfully for translational object keypoints, in this work, we show that naively applying relative supervision to the rotational group SO(3) will often fail to converge due to the non-convexity of the rotational space. To tackle this challenge, we propose a new algorithm for self-supervised orientation estimation which utilizes Modified Rodrigues Parameters to stereographically project the closed manifold of SO(3) to the open manifold of R3, allowing the optimization to be done in an open Euclidean space. We empirically validate the benefits of the proposed algorithm for rotational averaging problem in two settings: (1) direct optimization on rotation parameters, and (2) optimization of parameters of a convolutional neural network that predicts object orientations from images. In both settings, we demonstrate that our proposed algorithm is able to converge to a consistent relative orientation frame much faster than algorithms that purely operate in the SO(3) space.
Conference on Robot Learning (CoRL), 2022
|
|
Differentiable Raycasting for Self-supervised Occupancy Forecasting
Tarasha Khurana*, Peiyun Hu*, Achal Dave, Jason Ziglar, David Held, Deva Ramanan
European Conference on Computer Vision (ECCV), 2022
|

|
Learning to Singulate Layers of Cloth based on Tactile Feedback
Sashank Tirumala*, Thomas Weng*, Daniel Seita*, Oliver Kroemer, Zeynep Temel, David Held
@inproceedings{tirumala2022reskin,
author={Tirumala, Sashank and Weng, Thomas and Seita, Daniel and Kroemer, Oliver and Temel, Zeynep and Held, David},
booktitle={2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
title={Learning to Singulate Layers of Cloth using Tactile Feedback},
year={2022},
volume={},
number={},
pages={7773-7780},
doi={10.1109/IROS47612.2022.9981341}
}
Robotic manipulation of cloth has applications ranging from fabrics manufacturing to handling blankets and laundry. Cloth manipulation is challenging for robots largely due to their high degrees of freedom, complex dynamics, and severe self-occlusions when in folded or crumpled configurations. Prior work on robotic manipulation of cloth relies primarily on vision sensors alone, which may pose challenges for fine-grained manipulation tasks such as grasping a desired number of cloth layers from a stack of cloth. In this paper, we propose to use tactile sensing for cloth manipulation; we attach a tactile sensor (ReSkin) to one of the two fingertips of a Franka robot and train a classifier to determine whether the robot is grasping a specific number of cloth layers. During test-time experiments, the robot uses this classifier as part of its policy to grasp one or two cloth layers using tactile feedback to determine suitable grasping points. Experimental results over 180 physical trials suggest that the proposed method outperforms baselines that do not use tactile feedback and has a better generalization to unseen fabrics compared to methods that use image classifiers.
International Conference on Intelligent Robots and Systems (IROS), 2022 - Best Paper at ROMADO-SI
|

|
Learning Closed-loop Dough Manipulation using a Differentiable Reset Module
Carl Qi, Xingyu Lin, David Held
@article{qi2022dough, \nauthor={Qi, Carl and Lin, Xingyu and Held, David},\n\ journal={IEEE Robotics and Automation Letters}, \ntitle={Learning Closed-Loop\ \ Dough Manipulation Using a Differentiable Reset Module}, \nyear={2022},\nvolume={7},\n\ number={4},\npages={9857-9864},\ndoi={10.1109/LRA.2022.3191239}}"
Deformable object manipulation has many applications such as cooking and laundry folding in our daily lives. Manipulating elastoplastic objects such as dough is particularly challenging because dough lacks a compact state representation and requires contact-rich interactions. We consider the task of flattening a piece of dough into a specific shape from RGB-D images. While the task is seemingly intuitive for humans, there exist local optima for common approaches such as naive trajectory optimization. We propose a novel trajectory optimizer that optimizes through a differentiable "reset" module, transforming a single-stage, fixed-initialization trajectory into a multistage, multi-initialization trajectory where all stages are optimized jointly. We then train a closed-loop policy on the demonstrations generated by our trajectory optimizer. Our policy receives partial point clouds as input, allowing ease of transfer from simulation to the real world. We show that our policy can perform real-world dough manipulation, flattening a ball of dough into a target shape.
Robotics and Automation Letters (RAL) with presentation at the International Conference on Intelligent Robots and Systems (IROS), 2022
|

|
Visual Haptic Reasoning: Estimating Contact Forces by Observing Deformable Object Interactions
Yufei Wang, David Held, Zackory Erickson
@article{wang2022visual,
title={Visual Haptic Reasoning: Estimating Contact Forces by Observing Deformable Object Interactions},
author={Wang, Yufei and Held, David and Erickson, Zackory},
journal={IEEE Robotics and Automation Letters},
volume={7},
number={4},
pages={11426--11433},
year={2022},
publisher={IEEE}
}
Robotic manipulation of highly deformable cloth presents a promising opportunity to assist people with several daily tasks, such as washing dishes; folding laundry; or dressing, bathing, and hygiene assistance for individuals with severe motor impairments. In this work, we introduce a formulation that enables a collaborative robot to perform visual haptic reasoning with cloth -- the act of inferring the location and magnitude of applied forces during physical interaction. We present two distinct model representations, trained in physics simulation, that enable haptic reasoning using only visual and robot kinematic observations. We conducted quantitative evaluations of these models in simulation for robot-assisted dressing, bathing, and dish washing tasks, and demonstrate that the trained models can generalize across different tasks with varying interactions, human body sizes, and object shapes. We also present results with a real-world mobile manipulator, which used our simulation-trained models to estimate applied contact forces while performing physically assistive tasks with cloth.
Robotics and Automation Letters (RAL) with presentation at the International Conference on Intelligent Robots and Systems (IROS), 2022
|

|
FlowBot3D: Learning 3D Articulation Flow to Manipulate Articulated Objects
Ben Eisner*, Harry Zhang*, David Held
@inproceedings{EisnerZhang2022FLOW,\n title={FlowBot3D: Learning\ \ 3D Articulation Flow to Manipulate Articulated Objects},\n author={Eisner*,\ \ Ben and Zhang*, Harry and Held,David},\n booktitle={Robotics: Science\ \ and Systems (RSS)},\n year={2022}\n }"
We explore a novel method to perceive and manipulate 3D articulated objects that generalizes to enable a robot to articulate unseen classes of objects. We propose a vision-based system that learns to predict the potential motions of the parts of a variety of articulated objects to guide downstream motion planning of the system to articulate the objects. To predict the object motions, we train a neural network to output a dense vector field representing the point-wise motion direction of the points in the point cloud under articulation. We then deploy an analytical motion planner based on this vector field to achieve a policy that yields maximum articulation. We train the vision system entirely in simulation, and we demonstrate the capability of our system to generalize to unseen object instances and novel categories in both simulation and the real world, deploying our policy on a Sawyer robot with no finetuning. Results show that our system achieves state-of-the-art performance in both simulated and real-world experiments.
Robotics: Science and Systems (RSS), 2022 - Best Paper Finalist (Selection Rate 1.5%)
|
|
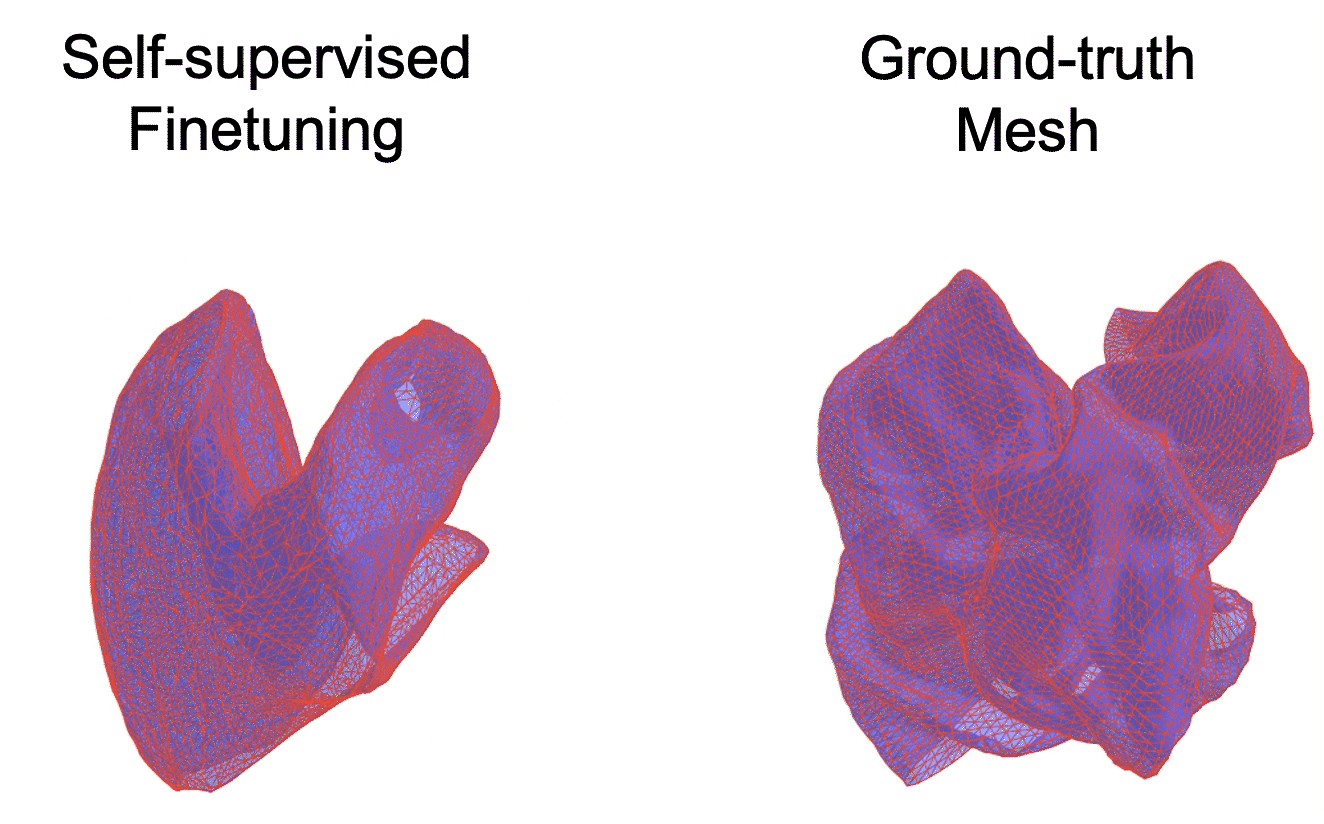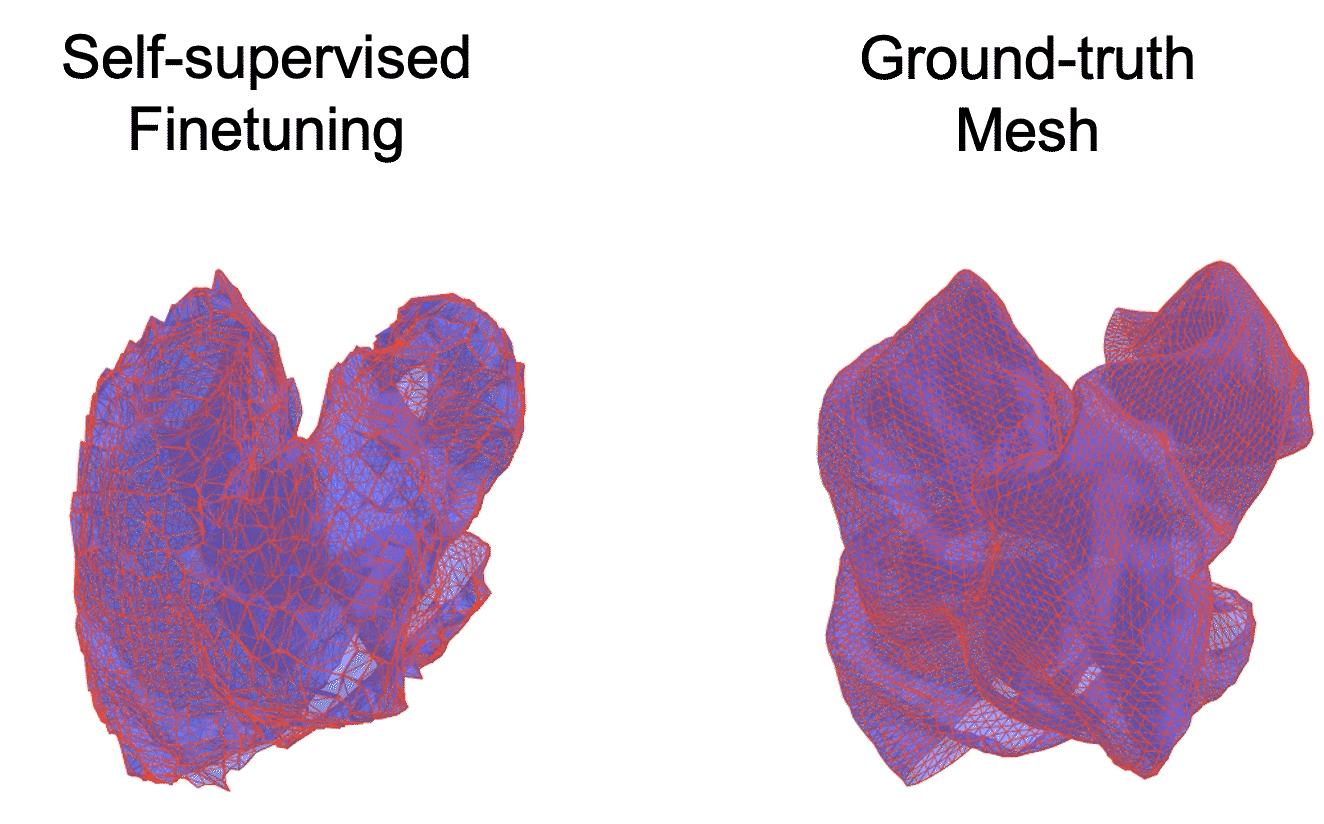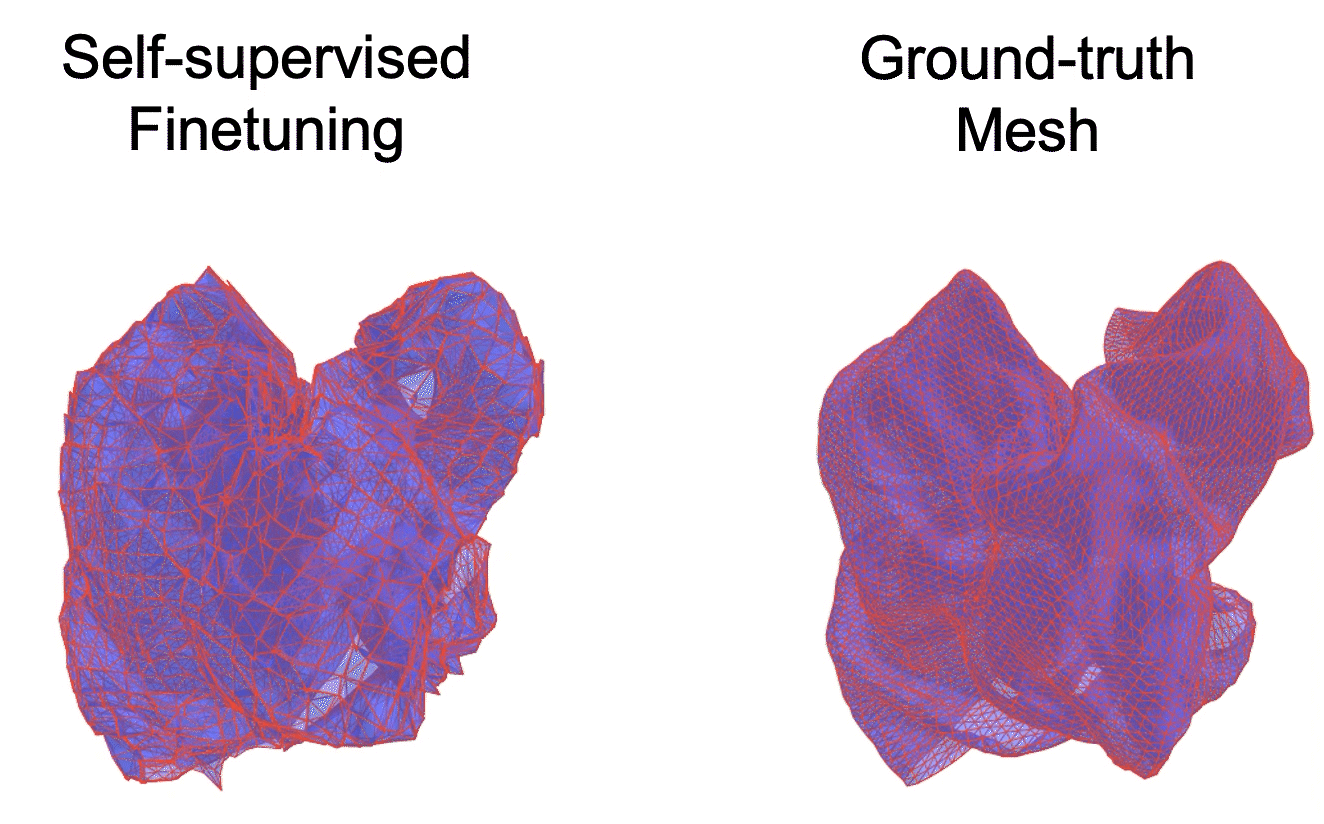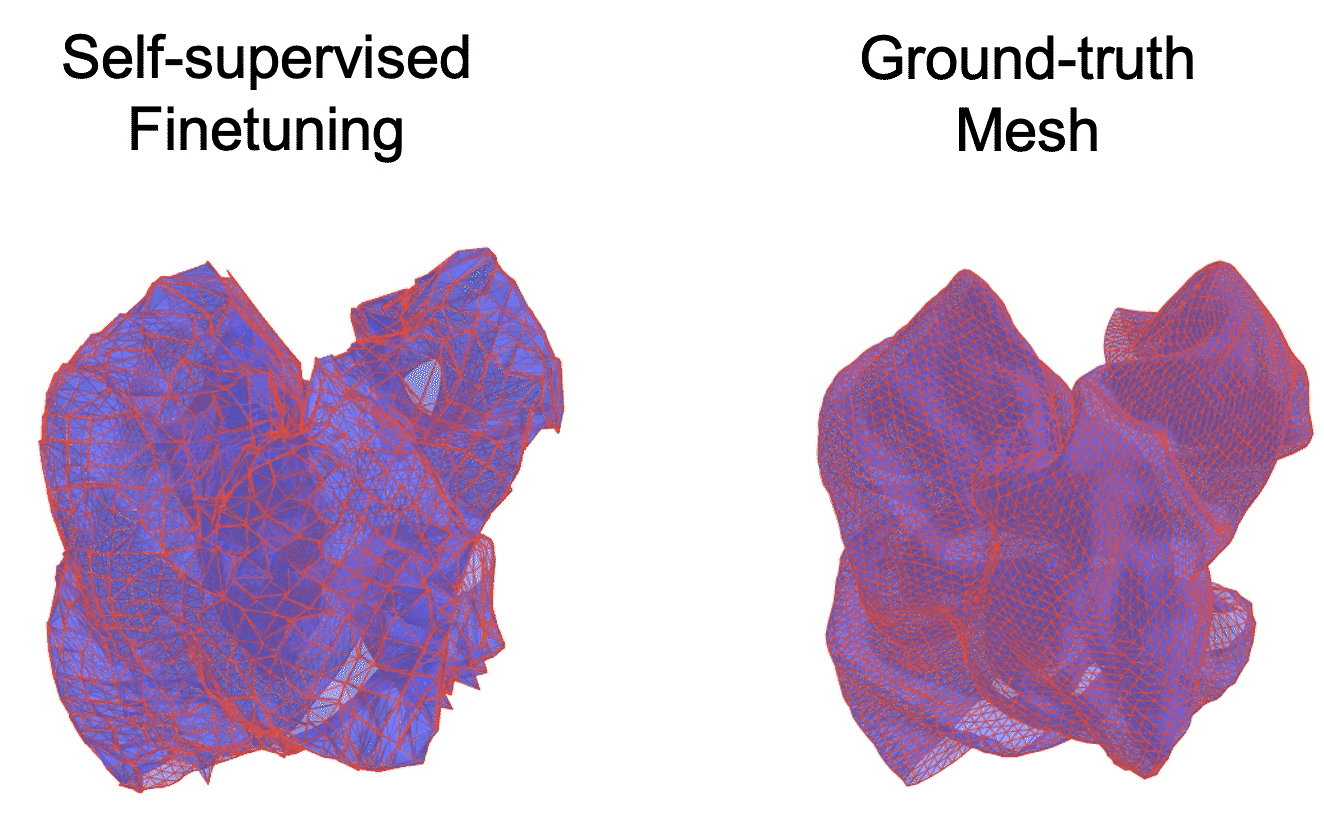
Mesh-based Dynamics with Occlusion Reasoning for Cloth Manipulation
Zixuan Huang, Xingyu Lin, David Held
@inproceedings{huang2022medor,\n title={Mesh-based Dynamics Model\ \ with Occlusion Reasoning for Cloth Manipulation},\n author={Huang,\ \ Zixuan and Lin, Xingyu and Held,David},\n booktitle={Robotics: Science\ \ and Systems (RSS)},\n year={2022}\n }"
Self-occlusion is challenging for cloth manipulation, as it makes it difficult to estimate the full state of the cloth. Ideally, a robot trying to unfold a crumpled or folded cloth should be able to reason about the cloth's occluded regions.
We leverage recent advances in pose estimation for cloth to build a system that uses explicit occlusion reasoning to unfold a crumpled cloth. Specifically, we first learn a model to reconstruct the mesh of the cloth. However, the model will likely have errors due to the complexities of the cloth configurations and due to ambiguities from occlusions. Our main insight is that we can further refine the predicted reconstruction by performing test-time finetuning with self-supervised losses. The obtained reconstructed mesh allows us to use a mesh-based dynamics model for planning while reasoning about occlusions. We evaluate our system both on cloth flattening as well as on cloth canonicalization, in which the objective is to manipulate the cloth into a canonical pose. Our experiments show that our method significantly outperforms prior methods that do not explicitly account for occlusions or perform test-time optimization.
Robotics: Science and Systems (RSS), 2022
|
|
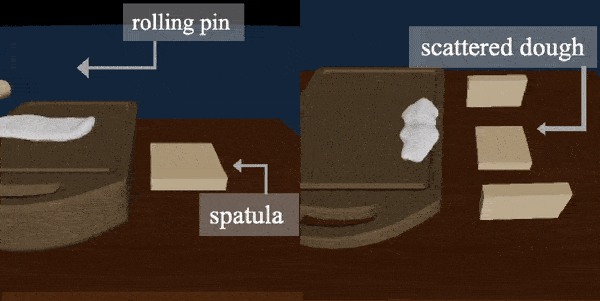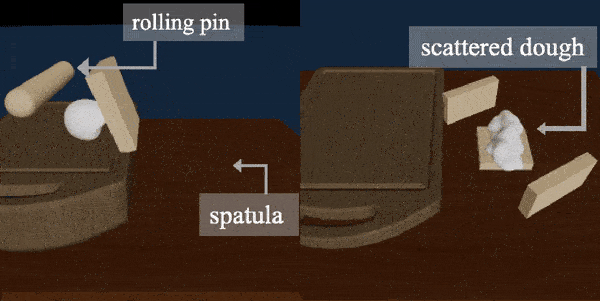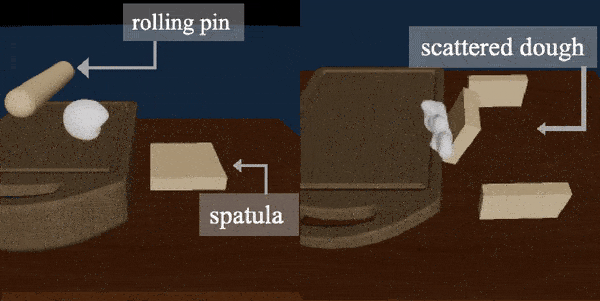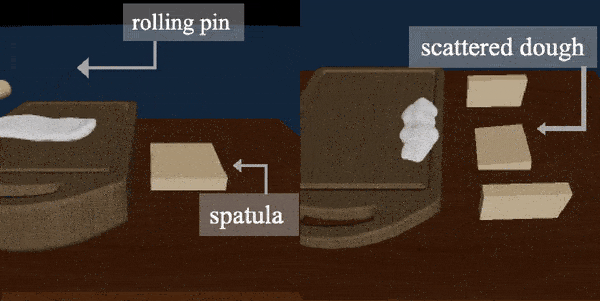
DiffSkill: Skill Abstraction from Differentiable Physics for Deformable Object Manipulations with Tools
Xingyu Lin, Zhiao Huang, Yunzhu Li, Joshua B. Tenenbaum, David Held, Chuang Gan
@inproceedings{
lin2022diffskill,
title={DiffSkill: Skill Abstraction from Differentiable Physics for Deformable Object Manipulations with Tools},
author={Xingyu Lin and Zhiao Huang and Yunzhu Li and David Held and Joshua B. Tenenbaum and Chuang Gan},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=Kef8cKdHWpP}}
We consider the problem of sequential robotic manipulation of deformable objects using tools.
Previous works have shown that differentiable physics simulators provide gradients to the environment state and help trajectory optimization to converge orders of magnitude faster than model-free reinforcement learning algorithms for deformable object manipulations. However, such gradient-based trajectory optimization typically requires access to the full simulator states and can only solve short-horizon, single-skill tasks due to local optima. In this work, we propose a novel framework, named DiffSkill, that uses a differentiable physics simulator for skill abstraction to solve long-horizon deformable object manipulation tasks from sensory observations. In particular, we first obtain short-horizon skills for using each individual tool from a gradient-based optimizer and then learn a neural skill abstractor from the demonstration videos; Finally, we plan over the skills to solve the long-horizon task. We show the advantages of our method in a new set of sequential deformable object manipulation tasks over previous reinforcement learning algorithms and the trajectory optimizer.
International Conference on Learning Representations (ICLR), 2022
|

|
Self-supervised Transparent Liquid Segmentation for Robotic Pouring
Gautham Narayan Narasimhan, Kai Zhang, Ben Eisner, Xingyu Lin, David Held
@inproceedings{icra2022pouring,
title={Self-supervised Transparent Liquid Segmentation for Robotic Pouring},
author={Gautham Narayan Narasimhan, Kai Zhang, Ben Eisner, Xingyu Lin, David Held},
booktitle={International Conference on Robotics and Automation (ICRA)},
year={2022}}
Liquid state estimation is important for robotics tasks such as pouring; however, estimating the state of transparent liquids is a challenging problem. We propose a novel segmentation pipeline that can segment transparent liquids such as water from a static, RGB image without requiring any manual annotations or heating of the liquid for training. Instead, we use a generative model that is capable of translating images of colored liquids into synthetically generated transparent liquid images, trained only on an unpaired dataset of colored and transparent liquid images. Segmentation labels of colored liquids are obtained automatically using background subtraction. Our experiments show that we are able to accurately predict a segmentation mask for transparent liquids without requiring any manual annotations. We demonstrate the utility of transparent liquid segmentation in a robotic pouring task that controls pouring by perceiving the liquid height in a transparent cup. Accompanying video and supplementary materials can be found on our project page.
International Conference of Robotics and Automation (ICRA), 2022
|
|
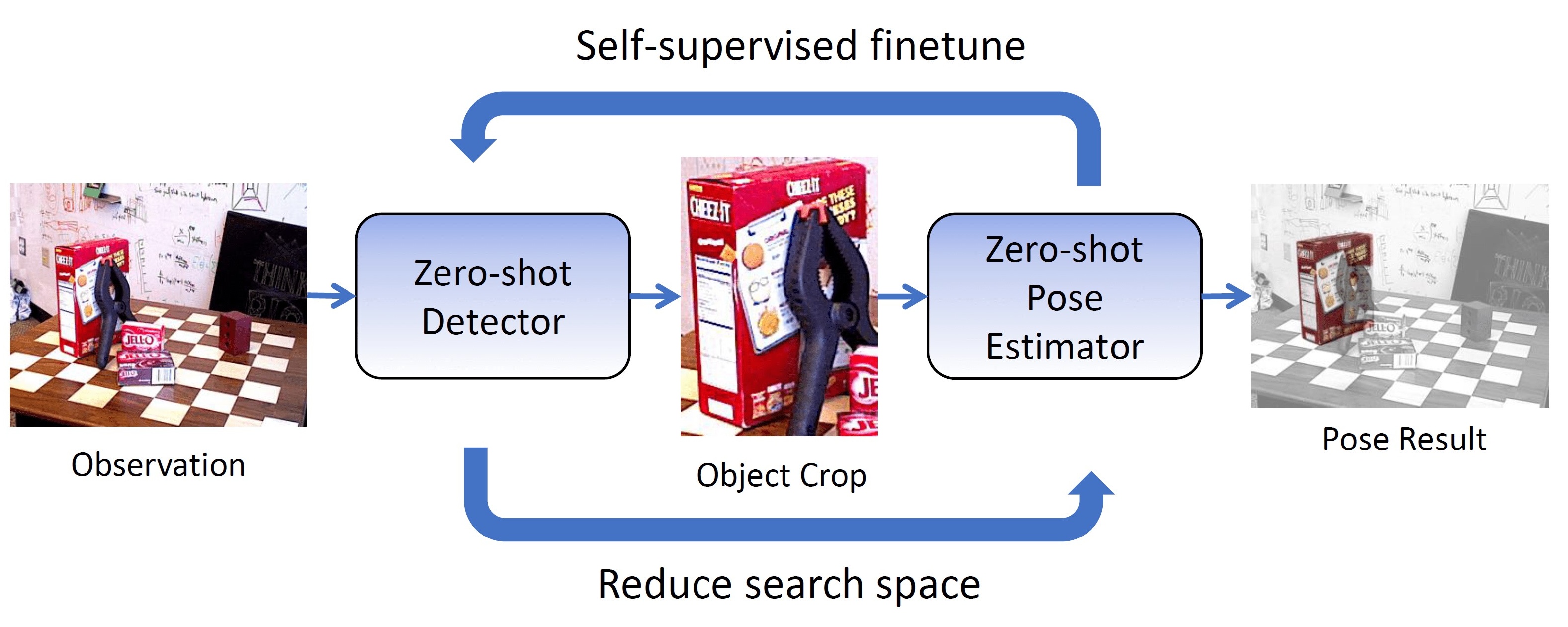
OSSID: Online Self-Supervised Instance Detection by (and for) Pose Estimation
Qiao Gu, Brian Okorn, David Held
@article{ral2022ossid,\n author={Gu, Qiao and Okorn, Brian and Held, David},\n\
journal={IEEE Robotics and Automation Letters}, \n title={OSSID: Online Self-Supervised\
\ Instance Detection by (And For) Pose Estimation}, \n year={2022},\n volume={7},\n\ \ number={2},\n pages={3022-3029},\n doi={10.1109/LRA.2022.3145488}}"
Real-time object pose estimation is necessary for many robot manipulation algorithms. However, state-of-the-art methods for object pose estimation are trained for a specific set of objects; these methods thus need to be retrained to estimate the pose of each new object, often requiring tens of GPU-days of training for optimal performance. In this paper, we propose the OSSID framework, leveraging a slow zero-shot pose estimator to self-supervise the training of a fast detection algorithm. This fast detector can then be used to filter the input to the pose estimator, drastically improving its inference speed. We show that this self-supervised training exceeds the performance of existing zero-shot detection methods on two widely used object pose estimation and detection datasets, without requiring any human annotations. Further, we show that the resulting method for pose estimation has a significantly faster inference speed, due to the ability to filter out large parts of the image. Thus, our method for self-supervised online learning of a detector (trained using pseudo-labels from a slow pose estimator) leads to accurate pose estimation at real-time speeds, without requiring human annotations.
Robotics and Automation Letters (RAL) with presentation at the International Conference of Robotics and Automation (ICRA), 2022
|

|
Self-Supervised Point Cloud Completion via Inpainting
Himangi Mittal, Brian Okorn, Arpit Jangid, David Held
@article{mittal2021self,\n title={Self-Supervised Point Cloud Completion\ \ via Inpainting},\n author={Mittal, Himangi and Okorn, Brian and Jangid, Arpit\ \ and Held, David},\n journal={British Machine Vision Conference (BMVC), 2021},\n\
year={2021}\n}"
When navigating in urban environments, many of the objects that need to be tracked and avoided are heavily occluded. Planning and tracking using these partial scans can be challenging. The aim of this work is to learn to complete these partial point clouds, giving us a full understanding of the object's geometry using only partial observations. Previous methods achieve this with the help of complete, ground-truth annotations of the target objects, which are available only for simulated datasets. However, such ground truth is unavailable for real-world LiDAR data. In this work, we present a self-supervised point cloud completion algorithm, PointPnCNet, which is trained only on partial scans without assuming access to complete, ground-truth annotations. Our method achieves this via inpainting. We remove a portion of the input data and train the network to complete the missing region. As it is difficult to determine which regions were occluded in the initial cloud and which were synthetically removed, our network learns to complete the full cloud, including the missing regions in the initial partial cloud. We show that our method outperforms previous unsupervised and weakly-supervised methods on both the synthetic dataset, ShapeNet, and real-world LiDAR dataset, Semantic KITTI.
British Machine Vision Conference (BMVC), 2021 - Oral presentation (Selection rate 3.3%)
|

|
RB2: Robotic Manipulation Benchmarking with a Twist
Sudeep Dasari, Jianren Wang, Joyce Hong, Shikhar Bahl, Yixin Lin, Austin S Wang, Abitha Thankaraj, Karanbir Singh Chahal, Berk Calli, Saurabh Gupta, David Held, Lerrel Pinto, Deepak Pathak, Vikash Kumar, Abhinav Gupta
Benchmarks offer a scientific way to compare algorithms using scientific performance metrics. Good benchmarks have two features: (a) wide audience appeal; (b) easily reproducible. In robotics, there is a tradeoff between reproducibility and broad accessibility. If the benchmark is kept restrictive (fixed hardware, objects), the numbers are reproducible but it becomes niche. On the other hand, benchmark could be just loose set of protocols but the underlying varying setups make it hard to reproduce the results. In this paper, we re-imagine robotics benchmarks – we define a robotics benchmark to be a set of experimental protocols and state of the art algorithmic implementations. These algorithm implementations will provide a way to recreate baseline numbers in a new local robotic setup in less than few hours and hence help provide credible relative rankings between different approaches. These credible local rankings are pooled from several locations to help establish global rankings and SOTA algorithms that work across majority of setups. We introduce RB2 — a benchmark inspired from human SHAP tests. Our benchmark was run across three different labs and reveals several surprising findings.
NeurIPS 2021 Datasets and Benchmarks Track, 2021
|
|
Semi-supervised 3D Object Detection via Temporal Graph Neural Networks
Jianren Wang, Haiming Gang, Siddharth Ancha, Yi-ting Chen, and David Held
@article{wang2021sodtgnn,
title={Semi-supervised 3D Object Detection via Temporal Graph Neural Networks},
author={Wang, Jianren and Gang, Haiming and Ancha, Siddharth and Chen, Yi-ting and Held, David},
journal={International Conference on 3D Vision (3DV)},
year={2021}}
3D object detection plays an important role in autonomous driving and other robotics applications. However, these detectors usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging large amounts of unlabeled point cloud videos by semi-supervised learning of 3D object detectors via temporal graph neural networks. Our insight is that temporal smoothing can create more accurate detection results on unlabeled data, and these smoothed detections can then be used to retrain the detector. We learn to perform this temporal reasoning with a graph neural network, where edges represent the relationship between candidate detections in different time frames.
International Conference on 3D Vision (3DV), 2021
|

|
Learning Visible Connectivity Dynamics for Cloth Smoothing
Xingyu Lin*, Yufei Wang*, Zixuan Huang, David Held
@inproceedings{lin2021VCD,
title={Learning Visible Connectivity Dynamics for Cloth Smoothing},
author={Lin, Xingyu and Wang, Yufei and Huang, Zixuan and Held, David},
booktitle={Conference on Robot Learning},
year={2021}}
Robotic manipulation of cloth remains challenging for robotics due to the complex dynamics of the cloth, lack of a low-dimensional state representation, and self-occlusions. In contrast to previous model-based approaches that learn a pixel-based dynamics model or a compressed latent vector dynamics, we propose to learn a particle-based dynamics model from a partial point cloud observation. To overcome the challenges of partial observability, we infer which visible points are connected on the underlying cloth mesh. We then learn a dynamics model over this visible connectivity graph. Compared to previous learning-based approaches, our model poses strong inductive bias with its particle based representation for learning the underlying cloth physics; it is invariant to visual features; and the predictions can be more easily visualized. We show that our method greatly outperforms previous state-of-the-art model-based and model-free reinforcement learning methods in simulation. Furthermore, we demonstrate zero-shot sim-to-real transfer where we deploy the model trained in simulation on a Franka arm and show that the model can successfully smooth different types of cloth from crumpled configurations. Videos can be found on our project website.
Conference on Robot Learning (CoRL), 2021
|

|
FabricFlowNet: Bimanual Cloth Manipulation with a Flow-based Policy
Thomas Weng, Sujay Bajracharya, Yufei Wang, David Held
@inproceedings{weng2021fabricflownet,\n title={FabricFlowNet: Bimanual Cloth\ \ Manipulation \n with a Flow-based Policy},\n author={Weng, Thomas and Bajracharya,\ \ Sujay and \n Wang, Yufei and Agrawal, Khush and Held, David},\n booktitle={Conference\ \ on Robot Learning},\n year={2021}\n}"
We address the problem of goal-directed cloth manipulation, a challenging task due to the deformability of cloth. Our insight is that optical flow, a technique normally used for motion estimation in video, can also provide an effective representation for corresponding cloth poses across observation and goal images. We introduce FabricFlowNet (FFN), a cloth manipulation policy that leverages flow as both an input and as an action representation to improve performance. FabricFlowNet also elegantly switches between dual-arm and single-arm actions based on the desired goal. We show that FabricFlowNet significantly outperforms state-of-the-art model-free and model-based cloth manipulation policies. We also present real-world experiments on a bimanual system, demonstrating effective sim-to-real transfer. Finally, we show that our method generalizes when trained on a single square cloth to other cloth shapes, such as T-shirts and rectangular cloths.
Conference on Robot Learning (CoRL), 2021
|
|
Learning Off-policy for Online Planning
Harshit Sikchi, Wenxuan Zhou, David Held
@inproceedings{sikchi2021learning,
title={Learning Off-policy for Online Planning},
author={Sikchi, Harshit and Zhou, Wenxuan and Held, David},
booktitle={Conference on Robot Learning},
year={2021}}
Reinforcement learning (RL) in low-data and risk-sensitive domains requires performant and flexible deployment policies that can readily incorporate constraints during deployment. One such class of policies are the semi-parametric H-step lookahead policies, which select actions using trajectory optimization over a dynamics model for a fixed horizon with a terminal value function. In this work, we investigate a novel instantiation of H-step lookahead with a learned model and a terminal value function learned by a model-free off-policy algorithm, named Learning Off-Policy with Online Planning (LOOP). We provide a theoretical analysis of this method, suggesting a tradeoff between model errors and value function errors and empirically demonstrate this tradeoff to be beneficial in deep reinforcement learning. Furthermore, we identify the "Actor Divergence" issue in this framework and propose Actor Regularized Control (ARC), a modified trajectory optimization procedure. We evaluate our method on a set of robotic tasks for Offline and Online RL and demonstrate improved performance. We also show the flexibility of LOOP to incorporate safety constraints during deployment with a set of navigation environments. We demonstrate that LOOP is a desirable framework for robotics applications based on its strong performance in various important RL settings.
Conference on Robot Learning (CoRL), 2021 - Oral presentation (Selection rate 6.5%); Best Paper Finalist
|

|
Active Safety Envelopes using Light Curtains with Probabilistic Guarantees
Siddharth Ancha, Gaurav Pathak, Srinivasa Narasimhan, David Held
@inproceedings{Ancha-RSS-21,\n AUTHOR = {Siddharth Ancha AND Gaurav\ \ Pathak AND Srinivasa G. Narasimhan AND David Held},\n TITLE = {Active\ \ Safety Envelopes using Light Curtains with Probabilistic Guarantees},\n BOOKTITLE\ \ = {Proceedings of Robotics: Science and Systems},\n YEAR = {2021},\n\ \ MONTH = {July}\n}"
To safely navigate unknown environments, robots must accurately perceive dynamic obstacles. Instead of directly measuring the scene depth with a LiDAR sensor, we explore the use of a much cheaper and higher resolution sensor:
Robotics: Science and Systems (RSS), 2021
|

|
ZePHyR: Zero-shot Pose Hypothesis Rating
Brian Okorn*, Qiao Gu*, Martial Hebert, David Held
@inproceedings{okorn2021zephyr,\n title={Zephyr: Zero-shot\ \ pose hypothesis rating},\n author={Okorn, Brian and Gu, Qiao\ \ and Hebert, Martial and Held, David},\n booktitle={2021 IEEE\ \ International Conference on Robotics and Automation (ICRA)},\n \ \ pages={14141--14148},\n year={2021},\n \ \ organization={IEEE}\n }"
Pose estimation is a basic module in many robot manipulation pipelines. Estimating the pose of objects in the environment can be useful for grasping, motion planning, or manipulation. However, current state-of-the-art methods for pose estimation either rely on large annotated training sets or simulated data. Further, the long training times for these methods prohibit quick interaction with novel objects. To address these issues, we introduce a novel method for zero-shot object pose estimation in clutter. Our approach uses a hypothesis generation and scoring framework, with a focus on learning a scoring function that generalizes to objects not used for training. We achieve zero-shot generalization by rating hypotheses as a function of unordered point differences. We evaluate our method on challenging datasets with both textured and untextured objects in cluttered scenes and demonstrate that our method significantly outperforms previous methods on this task. We also demonstrate how our system can be used by quickly scanning and building a model of a novel object, which can immediately be used by our method for pose estimation. Our work allows users to estimate the pose of novel objects without requiring any retraining.
International Conference of Robotics and Automation (ICRA), 2021
|

|
Exploiting & Refining Depth Distributions with Triangulation Light Curtains
Yaadhav Raaj, Siddharth Ancha, Robert Tamburo, David Held, Srinivasa Narasimhan
@inproceedings{cvpr2021raajexploiting,\n title = {Exploiting & Refining\ \ Depth Distributions with Triangulation Light Curtains},\n author = {Yaadhav\ \ Raaj, Siddharth Ancha, Robert Tamburo, David Held, Srinivasa Narasimhan},\n\ \ booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and\ \ Pattern Recognition (CVPR)},\n year = {2021}\n}"
Active sensing through the use of Adaptive Depth Sensors is a nascent field, with potential in areas such as Advanced driver-assistance systems (ADAS). They do however require dynamically driving a laser / light-source to a specific location to capture information, with one such class of sensor being the Triangulation Light Curtains (LC). In this work, we introduce a novel approach that exploits prior depth distributions from RGB cameras to drive a Light Curtain's laser line to regions of uncertainty to get new measurements. These measurements are utilized such that depth uncertainty is reduced and errors get corrected recursively. We show real-world experiments that validate our approach in outdoor and driving settings, and demonstrate qualitative and quantitative improvements in depth RMSE when RGB cameras are used in tandem with a Light Curtain.
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
|

|
Safe Local Motion Planning with Self-Supervised Freespace Forecasting
Peiyun Hu, Aaron Huang, John Dolan, David Held, Deva Ramanan
@inproceedings{cvpr2021husafe,\n title={Safe Local Motion\ \ Planning with Self-Supervised Freespace Forecasting},\n author={Peiyun\ \ Hu, Aaron Huang, John Dolan, David Held, Deva Ramanan},\n \
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern\
\ Recognition (CVPR)},\n year={2021}}"
Safe local motion planning for autonomous driving in dynamic environments requires forecasting how the scene evolves. Practical autonomy stacks adopt a semantic object-centric representation of a dynamic scene and build object detection, tracking, and prediction modules to solve forecasting. However, training these modules comes at an enormous human cost of manually annotated objects across frames. In this work, we explore future freespace as an alternative representation to support motion planning. Our key intuition is that it is important to avoid straying into occupied space regardless of what is occupying it. Importantly, computing ground-truth future freespace is annotation-free. First, we explore freespace forecasting as a self-supervised learning task. We then demonstrate how to use forecasted freespace to identify collision-prone plans from off-the-shelf motion planners. Finally, we propose future freespace as an additional source of annotation-free supervision. We demonstrate how to integrate such supervision into the learning process of learning-based planners. Experimental results on nuScenes and CARLA suggest both approaches lead to significant reduction in collision rates.
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
|
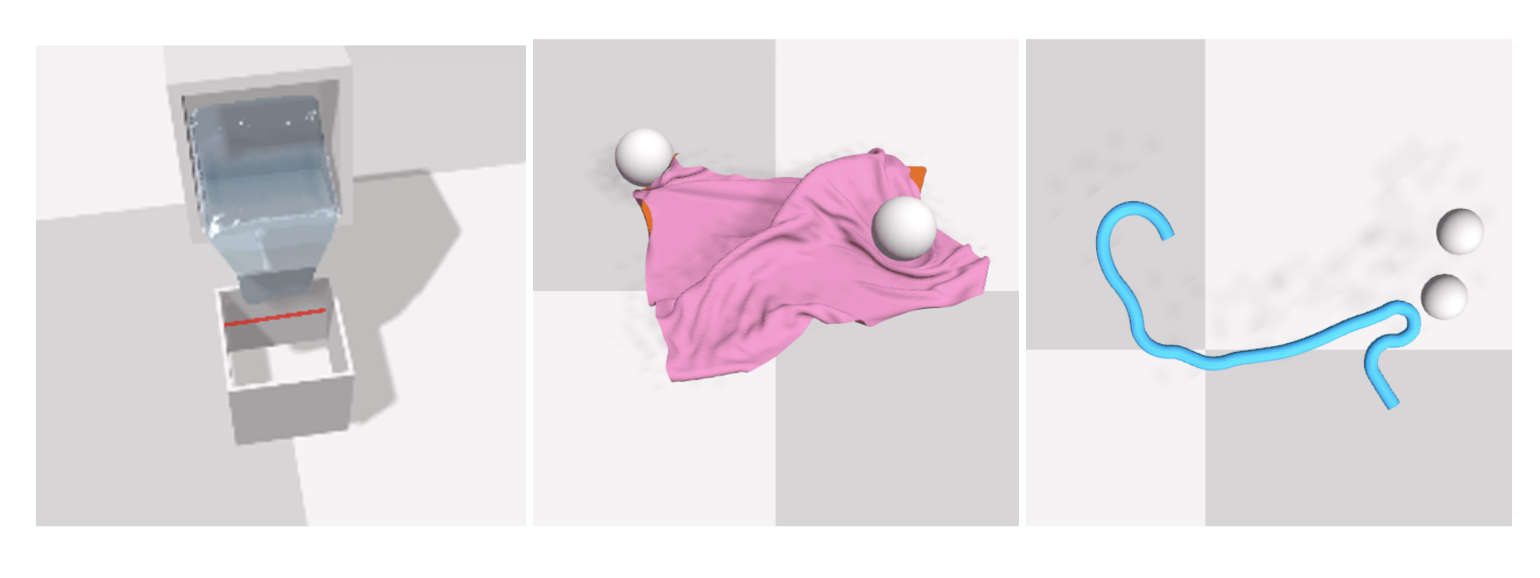
|
SoftGym: Benchmarking Deep Reinforcement Learning for Deformable Object Manipulation
Xingyu Lin, Yufei Wang, Jake Olkin, David Held
@inproceedings{corl2020softgym,
title={SoftGym: Benchmarking Deep Reinforcement Learning for Deformable Object Manipulation},
author={Lin, Xingyu and Wang, Yufei and Olkin, Jake and Held, David},
booktitle={Conference on Robot Learning},
year={2020}}
Manipulating deformable objects has long been a challenge in robotics due to its high dimensional state representation and complex dynamics. Recent success in deep reinforcement learning provides a promising direction for learning to manipulate deformable objects with data driven methods. However, existing reinforcement learning benchmarks only cover tasks with direct state observability and simple low-dimensional dynamics or with relatively simple image-based environments, such as those with rigid objects. In this paper, we present SoftGym, a set of open-source simulated benchmarks for manipulating deformable objects, with a standard OpenAI Gym API and a Python interface for creating new environments. Our benchmark will enable reproducible research in this important area. Further, we evaluate a variety of algorithms on these tasks and highlight challenges for reinforcement learning algorithms, including dealing with a state representation that has a high intrinsic dimensionality and is partially observable. The experiments and analysis indicate the strengths and limitations of existing methods in the context of deformable object manipulation that can help point the way forward for future methods development. Code and videos of the learned policies can be found on our project website.
Conference on Robot Learning (CoRL), 2020
|
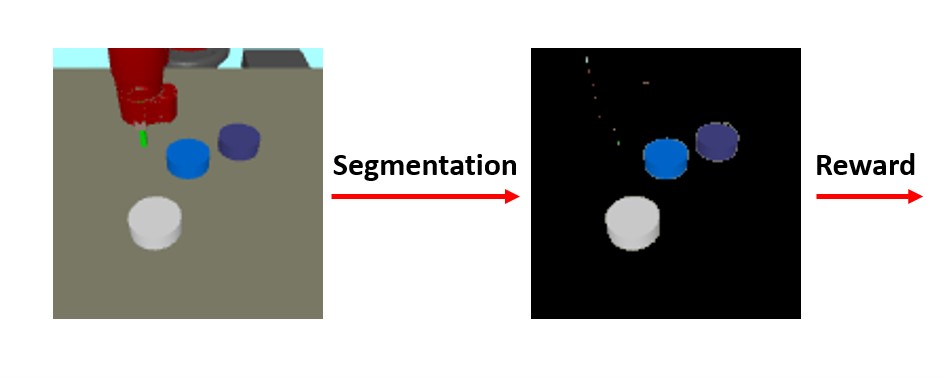
|
Visual Self-Supervised Reinforcement Learning with Object Reasoning
Yufei Wang*, Gautham Narayan Narasimhan*, Xingyu Lin, Brian Okorn, David Held
@inproceedings{corl2020roll,
title={ROLL: Visual Self-Supervised Reinforcement Learning with Object Reasoning},
author={Wang, Yufei and Narasimhan Gautham and Lin, Xingyu and Okorn, Brian and Held, David},
booktitle={Conference on Robot Learning},
year={2020}
}
Current image-based reinforcement learning (RL) algorithms typically operate on the whole image without performing object-level reasoning. This leads to inefficient goal sampling and ineffective reward functions. In this paper, we improve upon previous visual self-supervised RL by incorporating object-level reasoning and occlusion reasoning. Specifically, we use unknown object segmentation to ignore distractors in the scene for better reward computation and goal generation; we further enable occlusion reasoning by employing a novel auxiliary loss and training scheme. We demonstrate that our proposed algorithm, ROLL (Reinforcement learning with Object Level Learning), learns dramatically faster and achieves better final performance compared with previous methods in several simulated visual control tasks. Project video and code
are available at https://sites.google.com/andrew.cmu.edu/roll.
Conference on Robot Learning (CoRL), 2020
|

|
PLAS: Latent Action Space for Offline Reinforcement Learning
Wenxuan Zhou, Sujay Bajracharya, David Held
@inproceedings{PLAS_corl2020,
title={PLAS: Latent Action Space for Offline Reinforcement Learning},
author={Zhou, Wenxuan and Bajracharya, Sujay and Held, David},
booktitle={Conference on Robot Learning},
year={2020}
}
The goal of offline reinforcement learning is to learn a policy from a fixed dataset, without further interactions with the environment. This setting will be an increasingly more important paradigm for real-world applications of reinforcement learning such as robotics, in which data collection is slow and potentially dangerous. Existing off-policy algorithms have limited performance on static datasets due to extrapolation errors from out-of-distribution actions. This leads to the challenge of constraining the policy to select actions within the support of the dataset during training. We propose to simply learn the Policy in the Latent Action Space (PLAS) such that this requirement is naturally satisfied. We evaluate our method on continuous control benchmarks in simulation and a deformable object manipulation task with a physical robot. We demonstrate that our method provides competitive performance consistently across various continuous control tasks and different types of datasets, outperforming existing offline reinforcement learning methods with explicit constraints.
Conference on Robot Learning (CoRL), 2020 - Plenary talk (Selection rate 4.1%)
|

|
PanoNet3D: Combining Semantic and Geometric Understanding for LiDARPoint Cloud Detection
Xia Chen, Jianren Wang, David Held, Martial Hebert
@inproceedings{xia20panonet3d,\n author = \"Chen, Xia \n and Wang, Jianren\ \ \n and Held, David \n and Hebert, Martial\",\n title = \"PanoNet3D:\ \ Combining Semantic and Geometric Understanding for LiDARPoint Cloud Detection\"\ ,\n booktitle = \"3DV\",\n year = \"2020\"\n}"
Visual data in autonomous driving perception, such as camera image and LiDAR point cloud, can be interpreted as a mixture of two aspects: semantic feature and geometric structure. Semantics come from the appearance and context of objects to the sensor, while geometric structure is the actual 3D shape of point clouds. Most detectors on LiDAR point clouds focus only on analyzing the geometric structure of objects in real 3D space. Unlike previous works, we propose to learn both semantic feature and geometric structure via a unified multi-view framework. Our method exploits the nature of LiDAR scans -- 2D range images, and applies well-studied 2D convolutions to extract semantic features. By fusing semantic and geometric features, our method outperforms state-of-the-art approaches in all categories by a large margin. The methodology of combining semantic and geometric features provides a unique perspective of looking at the problems in real-world 3D point cloud detection.
International Conference on 3D Vision (3DV), 2020
|
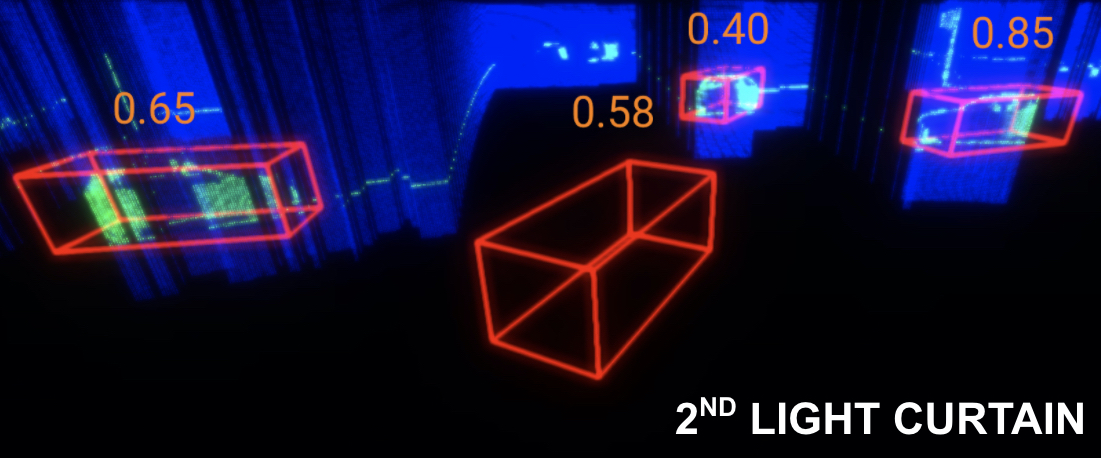
|
Active Perception using Light Curtains for Autonomous Driving
Siddharth Ancha, Yaadhav Raaj, Peiyun Hu, Srinivasa Narasimhan, David Held
@inproceedings{Ancha_2020_ECCV,\n author=\"Ancha, Siddharth\n and Raaj,\ \ Yaadhav\n and Hu, Peiyun\n and Narasimhan, Srinivasa G.\n and Held, David\"\ ,\n editor=\"Vedaldi, Andrea\n and Bischof, Horst\n and Brox, Thomas\n and\ \ Frahm, Jan-Michael\",\n title=\"Active Perception Using Light Curtains for\ \ Autonomous Driving\",\n booktitle=\"Computer Vision -- ECCV 2020\",\n year=\"\ 2020\",\n publisher=\"Springer International Publishing\",\n address=\"Cham\"\ ,\n pages=\"751--766\",\n isbn=\"978-3-030-58558-7\"\n}"
Most real-world 3D sensors such as LiDARs perform fixed scans of the entire environment, while being decoupled from the recognition system that processes the sensor data. In this work, we propose a method for 3D object recognition using light curtains, a resource-efficient controllable sensor that measures depth at user-specified locations in the environment. Crucially, we propose using prediction uncertainty of a deep learning based 3D point cloud detector to guide active perception. Given a neural network’s uncertainty, we derive an optimization objective to place light curtains using the principle of maximizing information gain. Then, we develop a novel and efficient optimization algorithm to maximize this objective by encoding the physical constraints of the device into a constraint graph and optimizing with dynamic programming. We show how a 3D detector can be trained to detect objects in a scene by sequentially placing uncertainty-guided light curtains to successively improve detection accuracy.
European Conference on Computer Vision (ECCV), 2020 - Spotlight presentation (Selection rate 5.3%)
|

|
Cloth Region Segmentation for Robust Grasp Selection
Jianing Qian*, Thomas Weng*, Luxin Zhang, Brian Okorn, David Held
@inproceedings{Qian_2020_IROS,\n author={Qian, Jianing and Weng, Thomas and Zhang, Luxin and Okorn, Brian and Held, David}, booktitle={2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, title={Cloth Region Segmentation for Robust Grasp Selection}, year={2020}, volume={}, number={}, pages={9553-9560}, doi={10.1109/IROS45743.2020.9341121}}"
Cloth detection and manipulation is a common task in domestic and industrial settings, yet such tasks remain a challenge for robots due to cloth deformability. Furthermore, in many cloth-related tasks like laundry folding and bed making, it is crucial to manipulate specific regions like edges and corners, as opposed to folds. In this work, we focus on the problem of segmenting and grasping these key regions. Our approach trains a network to segment the edges and corners of a cloth from a depth image, distinguishing such regions from wrinkles or folds. We also provide a novel algorithm for estimating the grasp location, direction, and directional uncertainty from the segmentation. We demonstrate our method on a real robot system and show that it outperforms baseline methods on grasping success. Video and other supplementary materials are available at:
International Conference on Intelligent Robots and Systems (IROS), 2020
|
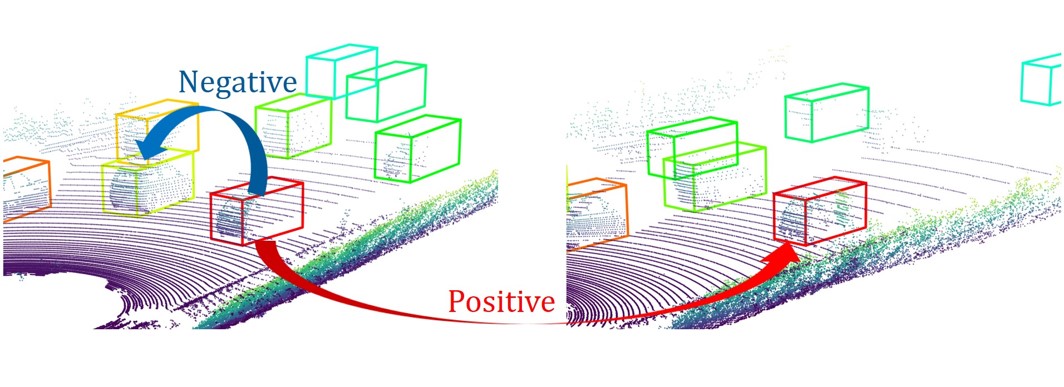
|
Uncertainty-aware Self-supervised 3D Data Association
Jianren Wang, Siddharth Ancha, Yi-Ting Chen, David Held
@inproceedings{jianren20s3da,\n author = \"Wang, Jianren \n and Ancha,\ \ Siddharth \n and Chen, Yi-Ting \n and Held, David\",\n title = \"Uncertainty-aware\ \ Self-supervised 3D Data Association\",\n booktitle = \"IROS\",\n year\ \ = \"2020\"\n}"
3D object trackers usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging vast unlabeled datasets by self-supervised metric learning of 3D object trackers, with a focus on data association. Large scale annotations for unlabeled data are cheaply obtained by automatic object detection and association across frames. We show how these self-supervised annotations can be used in a principled manner to learn point-cloud embeddings that are effective for 3D tracking. We estimate and incorporate uncertainty in self-supervised tracking to learn more robust embeddings, without needing any labeled data. We design embeddings to differentiate objects across frames, and learn them using uncertainty-aware self-supervised training. Finally, we demonstrate their ability to perform accurate data association across frames, towards effective and accurate 3D tracking.
International Conference on Intelligent Robots and Systems (IROS), 2020
|
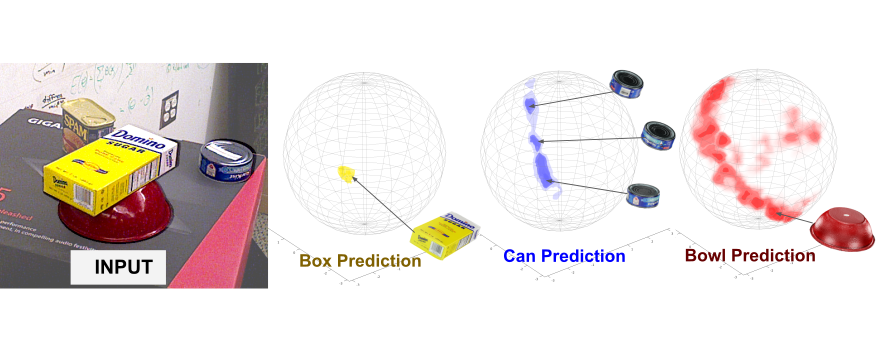
|
Learning Orientation Distributions for Object Pose Estimation
Brian Okorn, Mengyun Xu, Martial Hebert, David Held
International Conference on Intelligent Robots and Systems (IROS), 2020
|
|
3D Multi-Object Tracking: A Baseline and New Evaluation Metrics
Xinshuo Weng, Jianren Wang, David Held, Kris Kitani
@article{Weng2020_AB3DMOT, \nauthor = {Weng, Xinshuo and Wang, Jianren and\ \ Held, David and Kitani, Kris}, \njournal = {IROS}, \ntitle = {3D Multi-Object\ \ Tracking: A Baseline and New Evaluation Metrics}, \nyear = {2020} \n}"
3D multi-object tracking (MOT) is an essential component for many applications such as autonomous driving and assistive robotics. Recent work on 3D MOT focuses on developing accurate systems giving less attention to practical considerations such as computational cost and system complexity. In contrast, this work proposes a simple real-time 3D MOT system. Our system first obtains 3D detections from a LiDAR point cloud. Then, a straightforward combination of a 3D Kalman filter and the Hungarian algorithm is used for state estimation and data association. Additionally, 3D MOT datasets such as KITTI evaluate MOT methods in the 2D space and standardized 3D MOT evaluation tools are missing for a fair comparison of 3D MOT methods. Therefore, we propose a new 3D MOT evaluation tool along with three new metrics to comprehensively evaluate 3D MOT methods. We show that, although our system employs a combination of classical MOT modules, we achieve state-of-the-art 3D MOT performance on two 3D MOT benchmarks (KITTI and nuScenes). Surprisingly, although our system does not use any 2D data as inputs, we achieve competitive performance on the KITTI 2D MOT leaderboard. Our proposed system runs at a rate of 207.4 FPS on the KITTI dataset, achieving the fastest speed among all modern MOT systems.
International Conference on Intelligent Robots and Systems (IROS), 2020
|
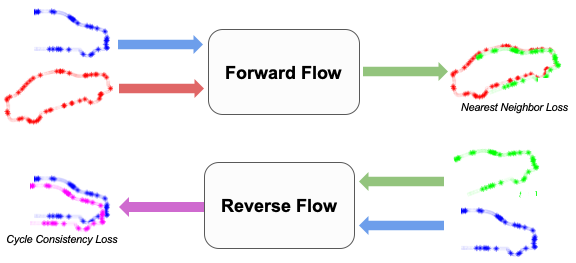
|
Just Go with the Flow: Self-Supervised Scene Flow Estimation
Himangi Mittal, Brian Okorn, David Held
@InProceedings{Mittal_2020_CVPR,
author = {Mittal, Himangi and Okorn, Brian and Held, David},
title = {Just Go With the Flow: Self-Supervised Scene Flow Estimation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}
}
When interacting with highly dynamic environments, scene flow allows autonomous systems to reason about the non-rigid motion of multiple independent objects. This is of particular interest in the field of autonomous driving, in which many cars, people, bicycles, and other objects need to be accurately tracked. Current state-of-the-art methods require annotated scene flow data from autonomous driving scenes to train scene flow networks with supervised learning. As an alternative, we present a method of training scene flow that uses two self-supervised losses, based on nearest neighbors and cycle consistency. These self-supervised losses allow us to train our method on large unlabeled autonomous driving datasets; the resulting method matches current state-of-the-art supervised performance using no real world annotations and exceeds state-of-the-art performance when combining our self-supervised approach with supervised learning on a smaller labeled dataset.
Conference on Computer Vision and Pattern Recognition (CVPR), 2020 - Oral presentation (Selection rate 5.7%)
|
|
What You See is What You Get: Exploiting Visibility for 3D Object Detection
Peiyun Hu, Jason Ziglar, David Held, Deva Ramanan
Conference on Computer Vision and Pattern Recognition (CVPR), 2020 - Oral presentation (Selection rate 5.7%)
|

|
Multi-Modal Transfer Learning for Grasping Transparent and Specular Objects
Thomas Weng, Amith Pallankize, Yimin Tang, Oliver Kroemer, David Held
@ARTICLE{9001238,
author={Thomas Weng and Amith Pallankize and Yimin Tang and Oliver Kroemer and David Held},
journal={IEEE Robotics and Automation Letters},
title={Multi-Modal Transfer Learning for Grasping Transparent and Specular Objects},
year={2020},
volume={5},
number={3},
pages={3791-3798},
doi={10.1109/LRA.2020.2974686}}
State-of-the-art object grasping methods rely on depth sensing to plan robust grasps, but commercially available depth sensors fail to detect transparent and specular objects. To improve grasping performance on such objects, we introduce a method for learning a multi-modal perception model by bootstrapping from an existing uni-modal model. This transfer learning approach requires only a pre-existing uni-modal grasping model and paired multi-modal image data for training, foregoing the need for ground-truth grasp success labels nor real grasp attempts. Our experiments demonstrate that our approach is able to reliably grasp transparent and reflective objects. Video and supplementary material are available at
Robotics and Automation Letters (RAL) with presentation at the International Conference of Robotics and Automation (ICRA), 2020
|

|
Learning to Optimally Segment Point Clouds
Peiyun Hu, David Held*, Deva Ramanan*
Robotics and Automation Letters (RAL) with presentation at the International Conference of Robotics and Automation (ICRA), 2020
|

|
Combining Deep Learning and Verification for Precise Object Instance Detection
Siddharth Ancha*, Junyu Nan*, David Held
@inproceedings{FlowVerify2019CoRL,\n author = {Siddharth Ancha and\n \ \ Junyu Nan and\n David Held},\n editor = {Leslie\ \ Pack Kaelbling and\n Danica Kragic and\n Komei Sugiura},\n\
title = {Combining Deep Learning and Verification for Precise Object Instance\n\
\ Detection},\n booktitle = {3rd Annual Conference on Robot Learning,\ \ CoRL 2019, Osaka, Japan,\n October 30 - November 1, 2019, Proceedings},\n\ \ series = {Proceedings of Machine Learning Research},\n volume = {100},\n\ \ pages = {122--141},\n publisher = ,\n year = {2019},\n url \ \ = {http://proceedings.mlr.press/v100/ancha20a.html},\n timestamp = {Mon,\ \ 25 May 2020 15:01:26 +0200},\n biburl = {https://dblp.org/rec/conf/corl/AnchaNH19.bib},\n\ \ bibsource = {dblp computer science bibliography, https://dblp.org}\n}"
Deep learning object detectors often return false positives with very high confidence. Although they optimize generic detection performance, such as mean average precision (mAP), they are not designed for reliability. For a reliable detection system, if a high confidence detection is made, we would want high certainty that the object has indeed been detected. To achieve this, we have developed a set of verification tests which a proposed detection must pass to be accepted. We develop a theoretical framework which proves that, under certain assumptions, our verification tests will not accept any false positives. Based on an approximation to this framework, we present a practical detection system that can verify, with high precision, whether each detection of a machine-learning based object detector is correct. We show that these tests can improve the overall accuracy of a base detector and that accepted examples are highly likely to be correct. This allows the detector to operate in a high precision regime and can thus be used for robotic perception systems as a reliable instance detection method.
Conference on Robot Learning (CoRL), 2019
|
|
Adaptive Auxiliary Task Weighting for Reinforcement Learning
Xingyu Lin*, Harjatin Baweja*, George Kantor, David Held
Neural Information Processing Systems (NeurIPS), 2019
|
|
Adaptive Variance for Changing Sparse-Reward Environments
Xingyu Lin, Pengsheng Guo, Carlos Florensa, David Held
International Conference of Robotics and Automation (ICRA), 2019
|

|
PCN: Point Completion Network - Best Paper Honorable Mention
Wentao Yuan, Tejas Khot, David Held, Christoph Mertz, Martial Hebert
International Conference on 3D Vision (3DV), 2018
|

|
Automatic Goal Generation for Reinforcement Learning Agents
Carlos Florensa*, David Held*, Xinyang Geng*, Pieter Abbeel
International Conference on Machine Learning (ICML), 2018
|
|
Enabling Robots to Communicate their Objectives
Sandy Han Huang, David Held, Pieter Abbeel, Anca D. Dragan
Autonomous Robotics (AURO), 2018
|

|
Reverse Curriculum Generation for Reinforcement Learning
Carlos Florensa, David Held, Markus Wulfmeier, Pieter Abbeel
Conference on Robot Learning (CoRL), 2017
|
|
Policy Transfer via Modularity
Ignasi Clavera*, David Held*, Pieter Abbeel
International Conference on Intelligent Robots and Systems (IROS), 2017
|

|
Constrained Policy Optimization
Joshua Achiam, David Held, Aviv Tamar, Pieter Abbeel
International Conference on Machine Learning (ICML), 2017
|
|
|
Enabling Robots to Communicate their Objectives
Sandy H. Huang, David Held, Pieter Abbeel, Anca D. Dragan
Robotics: Science and Systems (RSS), 2017
|
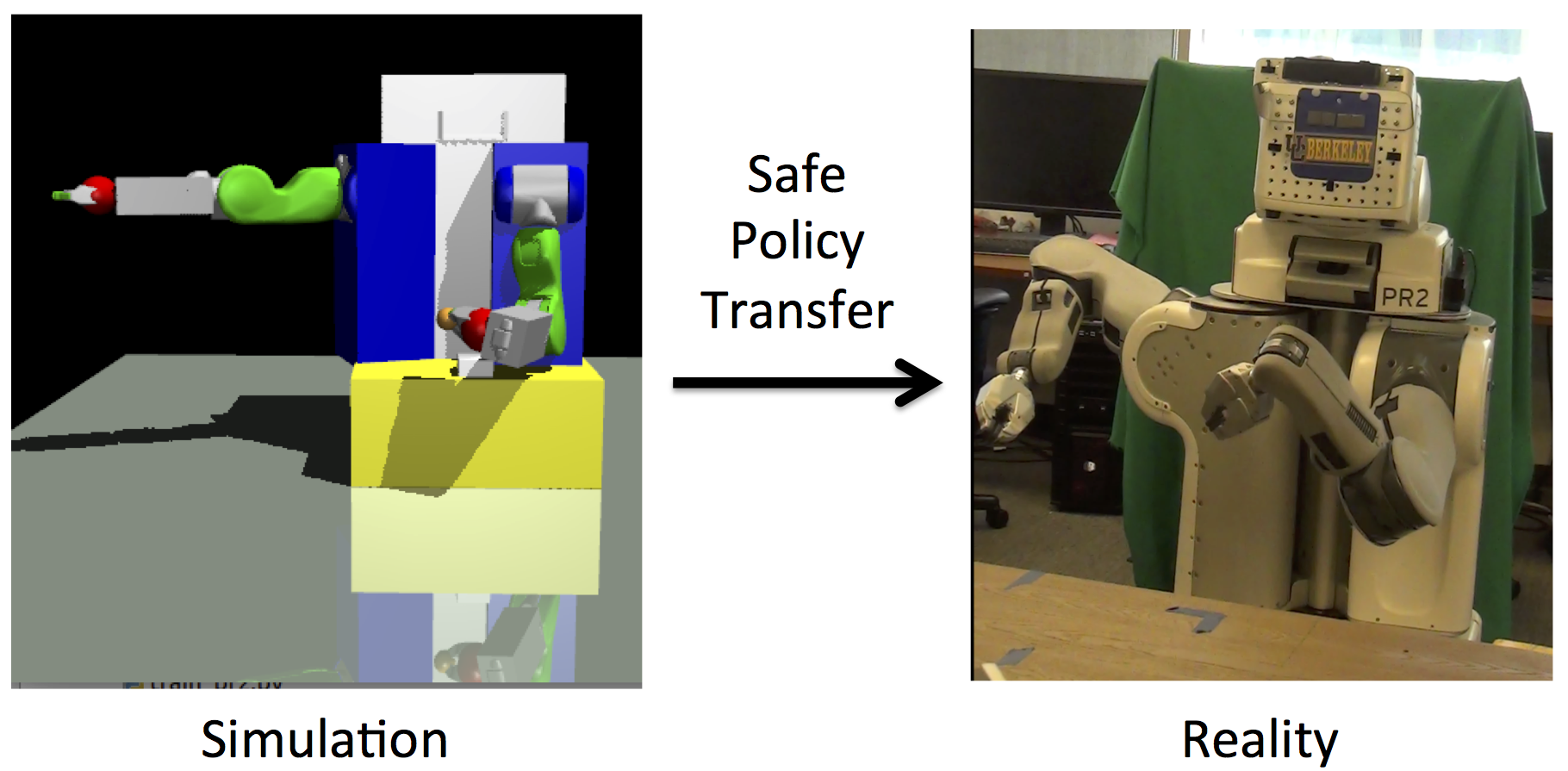
|
Probabilistically Safe Policy Transfer
David Held, Zoe McCarthy, Michael Zhang, Fred Shentu, Pieter Abbeel
International Conference on Robotics and Automation (ICRA), 2017
|
|
Learning to Track at 100 FPS with Deep Regression Networks
David Held, Sebastian Thrun, Silvio Savarese
European Conference on Computer Vision (ECCV), 2016
|
|
A Probabilistic Framework for Real-time 3D Segmentation using Spatial, Temporal, and Semantic Cues
David Held, Devin Guillory, Brice Rebsamen, Sebastian Thrun, Silvio Savarese
Robotics: Science and Systems (RSS), 2016
|

|
Robust Single-View Instance Recognition
David Held, Sebastian Thrun, Silvio Savarese
International Conference on Robotics and Automation (ICRA), 2016
|

|
Robust Real-Time Tracking Combining 3D Shape, Color, and Motion
David Held, Jesse Levinson, Sebastian Thrun, Silvio Savarese
International Journal of Robotics Research (IJRR), 2016
|

|
|

|
Precision Tracking with Sparse 3D and Dense Color 2D Data - Best Vision Paper Finalist
International Conference on Robotics and Automation
(ICRA), 2013
Precision tracking is important for predicting the
behavior of other cars in autonomous driving. We present a
novel method to combine laser and camera data to achieve
accurate velocity estimates of moving vehicles. We combine
sparse laser points with a high-resolution camera image to
obtain a dense colored point cloud. We use a color-augmented
search algorithm to align the dense color point clouds from
successive time frames for a moving vehicle, thereby obtaining
a precise estimate of the tracked vehicle’s velocity. Using this
alignment method, we obtain velocity estimates at a much
higher accuracy than previous methods. Through pre-filtering,
we are able to achieve near real time results. We also present an
online method for real-time use with accuracies close to that of
the full method. We present a novel approach to quantitatively
evaluate our velocity estimates by tracking a parked car in
a local reference frame in which it appears to be moving
relative to the ego vehicle. We use this evaluation method to
automatically quantitatively evaluate our tracking performance
on 466 separate tracked vehicles. Our method obtains a mean
absolute velocity error of 0.27 m/s and an RMS error of 0.47
m/s on this test set. We can also qualitatively evaluate our
method by building color 3D car models from moving vehicles.
We have thus demonstrated that our method can be used for
precision car tracking with applications to autonomous driving
and behavior modeling.
@inproceedings{2013-held-precision,
title = {Precision Tracking with Sparse 3D and Dense Color 2D Data},
author = {David Held and Jesse Levinson and Sebastian Thrun},
booktitle = {ICRA},
year = {2013} }
|

|
A Probabilistic Framework for Car Detection in Images using Context and Scale
International Conference on Robotics and Automation
(ICRA), 2012
Detecting cars in real-world images is an important task for autonomous driving, yet it remains unsolved. The system described in this paper takes advantage of context and scale to build a monocular single-frame image-based car detector that significantly outperforms the baseline. The system uses a probabilistic model to combine multiple forms of evidence for both context and scale to locate cars in a real-world image. We also use scale filtering to speed up our algorithm by a factor of 3.3 compared to the baseline. By using a calibrated camera and localization on a road map, we are able to obtain context and scale information from a single image without the use of a 3D laser. The system outperforms the baseline by an absolute 9.4% in overall average precision and 11.7% in average precision for cars smaller than 50 pixels in height, for which context and scale cues are especially important.
@INPROCEEDINGS{6224722,
author={Held, D. and Levinson, J. and Thrun, S.},
booktitle={Robotics and Automation (ICRA), 2012 IEEE International Conference on}, title={A probabilistic framework for car detection in images using context and scale},
year={2012},
month={may},
volume={},
number={},
pages={1628 -1634},
keywords={Cameras;Computational modeling;Context;Context modeling;Detectors;Roads;Training;automobiles;object detection;probability;traffic engineering computing;autonomous driving;car detection;context information;monocular single-frame image-based car detector;probabilistic framework;scale filtering;scale information;},
doi={10.1109/ICRA.2012.6224722},
ISSN={1050-4729}
}
|
|
Older Work
|
|
Characterizing Stiffness of Multi-Segment Flexible Arm Movements
International Conference on Robotics and Automation
(ICRA), 2012
A number of robotic studies have recently turned to biological inspiration in designing control schemes for flexible robots. Examples of such robots include continuous manipulators inspired by the octopus arm. However, the control strategies used by an octopus in moving its arms are still not fully understood. Starting from a dynamic model of an octopus arm and a given set of muscle activations, we develop a simulation technique to characterize the stiffness throughout a motion and at multiple points along the arm. By applying this technique to reaching and bending motions, we gain a number of insights that can help a control engineer design a biologically inspired impedance control scheme for a flexible robot arm. The framework developed is a general one that can be applied to any motion for any dynamic model. We also propose a theoretical analysis to efficiently estimate the stiffness analytically given a set of muscle activations. This analysis can be used to quickly evaluate the stiffness for new static configurations and dynamic movements.
@INPROCEEDINGS{6225070,
author={Held, D. and Yekutieli, Y. and Flash, T.},
booktitle={Robotics and Automation (ICRA), 2012 IEEE International Conference on}, title={Characterizing the stiffness of a multi-segment flexible arm during motion},
year={2012},
month={may},
volume={},
number={},
pages={3825 -3832},
keywords={Computational modeling;Force;Motion segmentation;Muscles;Shape;Trajectory;control system synthesis;dexterous manipulators;elasticity;flexible manipulators;manipulator dynamics;motion control;muscle;bending motion control;biologically inspired impedance control;control scheme design;dynamic movement;multisegment flexible robot arm;muscle activation;octopus arm;robot dynamic model;stiffness;},
doi={10.1109/ICRA.2012.6225070},
ISSN={1050-4729}
}
|

|
Towards fully autonomous driving: Systems and algorithms
Jesse Levinson, Jake Askeland, Jan Becker, Jennifer Dolson, David Held, Soeren Kammel,
J. Zico Kolter, Dirk Langer, Oliver Pink, Vaughan Pratt, Michael Sokolsky,
Ganymed Stanek, David Stavens, Alex Teichman, Moritz Werling, and Sebastian Thrun
Intelligent Vehicles Symposium (IV), 2011.
In order to achieve autonomous operation of a vehicle in urban situations with unpredictable traffic, several realtime systems must interoperate, including environment perception, localization, planning, and control. In addition, a robust vehicle platform with appropriate sensors, computational hardware, networking, and software infrastructure is essential. We previously published an overview of Junior, Stanford's entry in the 2007 DARPA Urban Challenge. This race was a closed-course competition which, while historic and inciting much progress in the field, was not fully representative of the situations that exist in the real world. In this paper, we present a summary of our recent research towards the goal of enabling safe and robust autonomous operation in more realistic situations. First, a trio of unsupervised algorithms automatically calibrates our 64-beam rotating LIDAR with accuracy superior to tedious hand measurements. We then generate high-resolution maps of the environment which are subsequently used for online localization with centimeter accuracy. Improved perception and recognition algorithms now enable Junior to track and classify obstacles as cyclists, pedestrians, and vehicles; traffic lights are detected as well. A new planning system uses this incoming data to generate thousands of candidate trajectories per second, choosing the optimal path dynamically. The improved controller continuously selects throttle, brake, and steering actuations that maximize comfort and minimize trajectory error. All of these algorithms work in sun or rain and during the day or night. With these systems operating together, Junior has successfully logged hundreds of miles of autonomous operation in a variety of real-life conditions.
@INPROCEEDINGS{5940562,
author={Levinson, J. and Askeland, J. and Becker, J. and Dolson, J. and Held, D. and Kammel, S. and Kolter, J.Z. and Langer, D. and Pink, O. and Pratt, V. and Sokolsky, M. and Stanek, G. and Stavens, D. and Teichman, A. and Werling, M. and Thrun, S.},
booktitle={Intelligent Vehicles Symposium (IV), 2011 IEEE}, title={Towards fully autonomous driving: Systems and algorithms},
year={2011},
month={june},
volume={},
number={},
pages={163 -168},
keywords={Calibration;Laser beams;Planning;Software;Trajectory;Vehicle dynamics;Vehicles;computer vision;mobile robots;remotely operated vehicles;DARPA urban challenge;LIDAR;autonomous driving;closed-course competition;environment perception;obstacle classification;obstacle tracking;online localization;planning system;realtime system;recognition algorithm;robust autonomous operation;robust vehicle platform;software infrastructure;unpredictable traffic;},
doi={10.1109/IVS.2011.5940562},
ISSN={1931-0587}}
|
|
MVWT-II: The Second Generation Caltech Multi-Vehicle Wireless Testbed
Zhipu Jinh, Stephen Waydo, Elisabeth B. Wildanger, Michael Lammers,
Hans Scholze, Peter Foley,
David Held,
Richard M. Murray
American Control Conference (ACC), 2004
The Caltech Multi-Vehicle Wireless Testbed is an experimental platform for validating theoretical advances in multiple-vehicle coordination and cooperation, real-time networked control system, and distributed computation. This paper describes the design and development of an additional fleet of 12 second-generation vehicles. These vehicles are hovercrafts and designed to have lower mass and friction as well as smaller size than the first generation vehicles. These hovercrafts combined with the outdoor wireless testbed provide a perfect hardware platform for RoboFlag competition.
@INPROCEEDINGS{1384698,
author={Jin, Z. and Waydo, S. and Wildanger, E.B. and Lammers, M. and Scholze, H. and Foley, P. and Held, D. and Murray, R.M.},
booktitle={American Control Conference, 2004. Proceedings of the 2004}, title={MVWT-II: the second generation Caltech Multi-Vehicle Wireless Testbed},
year={2004},
month={30 2004-july 2},
volume={6},
number={},
pages={5321 -5326 vol.6},
keywords={design engineering;games of skill;hovercraft;mobile robots;multi-robot systems;real-time systems;Caltech MultiVehicle Wireless Testbed;RoboFlag competition;distributed computation;hardware platform;hovercraft design;multivehicle cooperation;multivehicle coordination;outdoor wireless testbed;real time networked control system;second generation vehicles;},
doi={},
ISSN={0743-1619}}
|

|
Surface waves and spatial localization in vibrotactile displays
Haptics Symposium, 2010
The locus of vibrotactile stimulation is often used as an encoding cue in tactile displays developed for spatial orientation and navigation. However, the ability to localize the site of stimulation varies as a function of the number and configuration of the vibrating motors (tactors) in the display. As the inter-tactor distance decreases it has been found that the ability to localize a point of stimulation diminishes. One factor that may limit tactile localization is the surface wave elicited by vibration that propagates across the skin at a velocity that depends on the frequency of vibration and the viscoelastic properties of the skin. A material that simulates the stress-strain characteristics of human skin was used to measure the characteristics of surface waves during vibrotactile stimulation. Accelerometers glued to the simulated skin at fixed distances from the activated tactors were used to measure the amplitude of the acceleration as a function of distance as well as the propagation velocity. It was determined that at a distance of 60 mm from the site of activation, the surface wave was on average attenuated to less than 1 m/s^2. This suggests that for this type of tactor an inter-tactor distance of at least 60 mm would be optimal for a display in which the locus of stimulation is used as an encoding variable. It seems that much of the difficulty encountered in identifying the locus of a vibrotactile stimulus in multi-tactor displays may result from small intertactor distances.
@INPROCEEDINGS{5444673,
author={Jones, L.A. and Held, D. and Hunter, I.},
booktitle={Haptics Symposium, 2010 IEEE}, title={Surface waves and spatial localization in vibrotactile displays},
year={2010},
month={march},
volume={},
number={},
pages={91 -94},
keywords={Accelerometers;Displays;Elasticity;Encoding;Frequency;Humans;Navigation;Skin;Surface waves;Viscosity;accelerometers;haptic interfaces;accelerometers;distance 60 mm;inter-tactor distance;spatial localization;stimulation locus;stress-strain characteristics;surface waves;vibrating motors;vibrotactile displays;vibrotactile stimulation;localization;tactile display;tactons;torso;touch;},
doi={10.1109/HAPTIC.2010.5444673},
ISSN={}}
|

|
Characterization of Tactors Used in Vibrotactile Displays
Journal of Computing and Information Science in Engineering, 2008
A series of experiments was conducted to evaluate the operating characteristics of small DC motors that are often in tactile displays. The results indicated that these motors are reliable in terms of their frequency and amplitude of oscillation, but that the frequency varies across motors. A simulated skin material was developed to provide a substrate for evaluating the performance of the motors. There was a marked attenuation in frequency when the tactors were on this material and the surface waves could be detected 60 mm from the site of activation. These findings suggest that the spacing between tactors should be at least 60-80 mm if tactile cues are used to locate events in the environment.
@article{jones_held:044501,
author = {Lynette A. Jones and David A. Held},
collaboration = {},
title = {Characterization of Tactors Used in Vibrotactile Displays},
publisher = {ASME},
year = {2008},
journal = {Journal of Computing and Information Science in Engineering},
volume = {8},
number = {4},
eid = {044501},
numpages = {5},
pages = {044501},
keywords = {DC motors; display devices; haptic interfaces},
url = {http://link.aip.org/link/?CIS/8/044501/1},
doi = {10.1115/1.2988384}
}
|

![[Poster]](https://siddancha.github.io/projects/active-safety-envelopes-with-guarantees/docs/poster.png){kind=link}